SpringCloud
各大网站收录的不安全端口列表
1 | 1, // tcpmux |
CAP 原则与 BASE 理论
CAP 原则
[
CAP 原则又称 CAP 定理,指的是在一个分布式系统中, Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性),三者不可得兼。
CAP 由 Eric Brewer 在 2000 年 PODC 会议上提出。该猜想在提出两年后被证明成立,成为我们熟知的 CAP 定理。CAP 三者不可兼得。
| 特性 | 定理 |
|---|---|
| Consistency | 也叫做数据原子性,系统在执行某项操作后仍然处于一致的状态。在分布式系统中,更新操作执行成功后所有的用户都应该读到最新的值,这样的系统被认为是具有强一致性的。等同于所有节点访问同一份最新的数据副本。 |
| Availability | 每一个操作总是能够在一定的时间内返回结果,这里需要注意的是"一定时间内"和"返回结果”。一定时间内指的是,在可以容忍的范围内返回结果,结果可以是成功或者是失败。 |
| Partition tolerance | 在网络分区的情况下,被分隔的节点仍能正常对外提供服务(分布式集群,数据被分布存储在不同的服务器上,无论什么情况,服务器都能正常被访问)。 |
CAP的证明

如上图,是我们证明CAP的基本场景,网络中有两个节点N1和N2,可以简单的理解N1和N2分别是两台计算机,他们之间网络可以连通,N1中有一个应用程序A,和一个数据库V,N2也有一个应用程序B2和一个数据库V。现在,A和B是分布式系统的两个部分,V是分布式系统的数据存储的两个子数据库。
在满足一致性的时候,N1和N2中的数据是一样的,V0=V0。在满足可用性的时候,用户不管是请求N1或者N2,都会得到立即响应。在满足分区容错性的情况下,N1和N2有任何一方宕机,或者网络不通的时候,都不会影响N1和N2彼此之间的正常运作。

如上图,是分布式系统正常运转的流程,用户向N1机器请求数据更新,程序A更新数据库Vo为V1,分布式系统将数据进行同步操作M,将V1同步的N2中V0,使得N2中的数据V0也更新为V1,N2中的数据再响应N2的请求。
这里,可以定义N1和N2的数据库V之间的数据是否一样为一致性;外部对N1和N2的请求响应为可用行;N1和N2之间的网络环境为分区容错性。这是正常运作的场景,也是理想的场景,然而现实是残酷的,当错误发生的时候,一致性和可用性还有分区容错性,是否能同时满足,还是说要进行取舍呢?
作为一个分布式系统,它和单机系统的最大区别,就在于网络,现在假设一种极端情况,N1和N2之间的网络断开了,我们要支持这种网络异常,相当于要满足分区容错性,能不能同时满足一致性和响应性呢?还是说要对他们进行取舍。

假设在N1和N2之间网络断开的时候,有用户向N1发送数据更新请求,那N1中的数据V0将被更新为V1,由于网络是断开的,所以分布式系统同步操作M,所以N2中的数据依旧是V0;这个时候,有用户向N2发送数据读取请求,由于数据还没有进行同步,应用程序没办法立即给用户返回最新的数据V1,怎么办呢?
有二种选择,第一,牺牲数据一致性,保证可用性。响应旧的数据V0给用户;
第二,牺牲可用性,保证数据一致性。阻塞等待,直到网络连接恢复,数据更新操作M完成之后,再给用户响应最新的数据V1。
这个过程,证明了要满足分区容错性的分布式系统,只能在一致性和可用性两者中,选择其中一个。
取舍策略
CAP 三个特性只能满足其中两个,那么取舍的策略就共有三种:
- CA without P:如果不要求P(不允许分区),则C(强一致性)和A(可用性)是可以保证的。但放弃 P 的同时也就意味着放弃了系统的扩展性,也就是分布式节点受限,没办法部署子节点,这是违背分布式系统设计的初衷的。
- CP without A:如果不要求A(可用),相当于每个请求都需要在服务器之间保持强一致,而P(分区)会导致同步时间无限延长(也就是等待数据同步完才能正常访问服务),一旦发生网络故障或者消息丢失等情况,就要牺牲用户的体验,等待所有数据全部一致了之后再让用户访问系统。设计成 CP 的系统其实不少,最典型的就是分布式数据库,如 Redis、HBase 等。对于这些分布式数据库来说,数据的一致性是最基本的要求,因为如果连这个标准都达不到,那么直接采用关系型数据库就好,没必要再浪费资源来部署分布式数据库。
- AP without C:要高可用并允许分区,则需放弃一致性。一旦分区发生,节点之间可能会失去联系,为了高可用,每个节点只能用本地数据提供服务,而这样会导致全局数据的不一致性。典型的应用就如某米的抢购手机场景,可能前几秒你浏览商品的时候页面提示是有库存的,当你选择完商品准备下单的时候,系统提示你下单失败,商品已售完。这其实就是先在 A(可用性)方面保证系统可以正常的服务,然后在数据的一致性方面做了些牺牲,虽然多少会影响一些用户体验,但也不至于造成用户购物流程的严重阻塞。
总结
现如今,对于多数大型互联网应用的场景,主机众多、部署分散,而且现在的集群规模越来越大,节点只会越来越多,所以节点故障、网络故障是常态,因此分区容错性也就成为了一个分布式系统必然要面对的问题。那么就只能在 C 和 A 之间进行取舍。但对于传统的项目就可能有所不同,拿银行的转账系统来说,涉及到金钱的对于数据一致性不能做出一丝的让步,C 必须保证,出现网络故障的话,宁可停止服务,可以在 A 和 P 之间做取舍。
总而言之,没有最好的策略,好的系统应该是根据业务场景来进行架构设计的,只有适合的才是最好的。
BASE 理论
CAP 理论已经提出好多年了,难道真的没有办法解决这个问题吗?也许可以做些改变。比如 C 不必使用那么强的一致性,可以先将数据存起来,稍后再更新,实现所谓的 “最终一致性”。
这个思路又是一个庞大的问题,同时也引出了第二个理论 BASE 理论。
BASE:全称 Basically Available(基本可用),Soft state(软状态),和 Eventually consistent(最终一致性)三个短语的缩写,来自 ebay 的架构师提出。
BASE 理论是对 CAP 中一致性和可用性权衡的结果,其来源于对大型互联网分布式实践的总结,是基于 CAP 定理逐步演化而来的。其核心思想是:
既然无法做到强一致性(Strong consistency),但每个应用都可以根据自身的业务特点,采用适当的方式来使系统达到最终一致性(Eventual consistency)。
Basically Available(基本可用)
基本可用是指分布式系统在出现故障的时候,允许损失部分可用性(例如响应时间、功能上的可用性)。需要注意的是,基本可用绝不等价于系统不可用。
- 响应时间上的损失:正常情况下搜索引擎需要在 0.5 秒之内返回给用户相应的查询结果,但由于出现故障(比如系统部分机房发生断电或断网故障),查询结果的响应时间增加到了 1~2 秒。
- 功能上的损失:购物网站在购物高峰(如双十一)时,为了保护系统的稳定性,部分消费者可能会被引导到一个降级页面。
Soft state(软状态)
什么是软状态呢?相对于原子性而言,要求多个节点的数据副本都是一致的,这是一种 “硬状态”。
软状态是指允许系统存在中间状态,而该中间状态不会影响系统整体可用性。分布式存储中一般一份数据会有多个副本,允许不同副本数据同步的延时就是软状态的体现。
Eventually consistent(最终一致性)
系统不可能一直是软状态,必须有个时间期限。在期限过后,应当保证所有副本保持数据一致性。从而达到数据的最终一致性。这个时间期限取决于网络延时,系统负载,数据复制方案设计等等因素。
实际上,不只是分布式系统使用最终一致性,关系型数据库在某个功能上,也是使用最终一致性的,比如备份,数据库的复制都是需要时间的,这个复制过程中,业务读取到的值就是旧值。当然,最终还是达成了数据一致性。这也算是一个最终一致性的经典案例。
总结
总的来说,BASE 理论面向的是大型高可用可扩展的分布式系统,和传统事务的 ACID 是相反的,它完全不同于 ACID 的强一致性模型,而是通过牺牲强一致性来获得可用性,并允许数据在一段时间是不一致的。
一,微服务介绍

刚开始进入软件行业时还是单体应用的时代,前后端分离的概念都还没普及,开发的时候需要花大量的时间在“强大”的JSP上面,那时候SOA已经算是新技术了。现在,微服务已经大行其道,有哪个互联网产品不说自己是微服务架构呢?
但是,对于微服务的理解每个人都不太一样,这篇文章主要是聊一聊我对微服务的理解以及如何搭建经典的微服务架构,目的是梳理一下自己的一些想法,如果存在不同看法的欢迎指正!
什么是微服务
首先,什么是微服务呢?
单体应用
相对的,要理解什么是微服务,那么可以先理解什么是单体应用,在没有提出微服务的概念的“远古”年代,一个软件应用,往往会将应用所有功能都开发和打包在一起,那时候的一个B/S应用架构往往是这样的:

B/S
但是,当用户访问量变大导致一台服务器无法支撑时怎么办呢?加服务器加负载均衡,架构就变成这样了:

B/S+负载均衡
后面发现把静态文件独立出来,通过CDN等手段进行加速,可以提升应用的整体相应,单体应用的架构就变成:

上面3中架构都还是单体应用,只是在部署方面进行了优化,所以避免不了单体应用的根本的缺点:
- 代码臃肿,应用启动时间长;(代码超过1G的项目都有!)
- 回归测试周期长,修复一个小小bug可能都需要对所有关键业务进行回归测试。
- 应用容错性差,某个小小功能的程序错误可能导致整个系统宕机;
- 伸缩困难,单体应用扩展性能时只能整个应用进行扩展,造成计算资源浪费。
- 开发协作困难,一个大型应用系统,可能几十个甚至上百个开发人员,大家都在维护一套代码的话,代码merge复杂度急剧增加。
微服务
我认为任何技术的演进都是有迹可循的,任何新技术的出现都是为了解决原有技术无法解决的需求,所以,微服务的出现就是因为原来单体应用架构已经无法满足当前互联网产品的技术需求。
在微服务架构之前还有一个概念:SOA(Service-Oriented Architecture)-面向服务的体系架构。我认为的SOA只是一个架构模型的方法论,并不是一个明确而严谨的架构标准,只是后面很多人将SOA与The Open Group的SOA参考模型等同了,认为严格按照TOG-SOA标准的才算真正的SOA架构。SOA就已经提出的面向服务的架构思想,所以微服务应该算是SOA的一种演进吧。
撇开架构先不说,什么样的服务才算微服务呢?
- 单一职责的。一个微服务应该都是单一职责的,这才是“微”的体现,一个微服务解决一个业务问题(注意是一个业务问题而不是一个接口)。
- 面向服务的。将自己的业务能力封装并对外提供服务,这是继承SOA的核心思想,一个微服务本身也可能使用到其它微服务的能力。
我觉得满足以上两点就可以认为典型的微服务。
微服务典型架构
微服务架构,核心是为了解决应用微服务化之后的服务治理问题。
应用微服务化之后,首先遇到的第一个问题就是服务发现问题,一个微服务如何发现其他微服务呢?最简单的方式就是每个微服务里面配置其他微服务的地址,但是当微服务数量众多的时候,这样做明显不现实。所以需要使用到微服务架构中的一个最重要的组件:服务注册中心,所有服务都注册到服务注册中心,同时也可以从服务注册中心获取当前可用的服务清单:

服务注册中心
解决服务发现问题后,接着需要解决微服务分布式部署带来的第二个问题:服务配置管理的问题。当服务数量超过一定程度之后,如果需要在每个服务里面分别维护每一个服务的配置文件,运维人员估计要哭了。那么,就需要用到微服务架构里面第二个重要的组件:配置中心,微服务架构就变成下面这样了:

配置中心
以上应用内部的服务治理,当客户端或外部应用调用服务的时候怎么处理呢?服务A可能有多个节点,服务A、服务B和服务C的服务地址都不同,服务授权验证在哪里做?这时,就需要使用到服务网关提供统一的服务入口,最终形成典型微服务架构:

典型微服务架构
上面是一个典型的微服务架构,当然微服务的服务治理还涉及很多内容,比如:
- 通过熔断、限流等机制保证高可用;
- 微服务之间调用的负载均衡;
- 分布式事务(2PC、3PC、TCC、LCN等);
- 服务调用链跟踪等等。
微服务框架
目前国内企业使用的微服务框架主要是Spring Cloud和Dubbo(或者DubboX),但是Dubbo那两年的停更严重打击了开发人员对它的信心,Spring Cloud已经逐渐成为主流,比较两个框架的优劣势的文章在网上有很多,这里就不重复了,选择什么框架还是按业务需求来吧,业务框架决定技术框架。
Spring Cloud全家桶提供了各种各样的组件,基本可以覆盖微服务的服务治理的方方面面,以下列出了Spring Cloud一些常用组件:

二,SpringCloud介绍
 总体架构
总体架构
什么是Spring cloud
构建分布式系统不需要复杂和容易出错。Spring Cloud 为最常见的分布式系统模式提供了一种简单且易于接受的编程模型,帮助开发人员构建有弹性的、可靠的、协调的应用程序。Spring Cloud 构建于 Spring Boot 之上,使得开发者很容易入手并快速应用于生产中。
官方果然官方,介绍都这么有板有眼的。
我所理解的 Spring Cloud 就是微服务系统架构的一站式解决方案,在平时我们构建微服务的过程中需要做如 服务发现注册 、配置中心 、消息总线 、负载均衡 、断路器 、数据监控 等操作,而 Spring Cloud 为我们提供了一套简易的编程模型,使我们能在 Spring Boot 的基础上轻松地实现微服务项目的构建。
Spring Cloud 的版本
当然这个只是个题外话。
Spring Cloud 的版本号并不是我们通常见的数字版本号,而是一些很奇怪的单词。这些单词均为英国伦敦地铁站的站名。同时根据字母表的顺序来对应版本时间顺序,比如:最早 的 Release 版本 Angel,第二个 Release 版本 Brixton(英国地名),然后是 Camden、 Dalston、Edgware、Finchley、Greenwich、Hoxton。
三,Eureka
Spring Cloud 的服务发现框架——Eureka
Eureka是基于REST(代表性状态转移)的服务,主要在AWS云中用于定位服务,以实现负载均衡和中间层服务器的故障转移。我们称此服务为Eureka服务器。Eureka还带有一个基于Java的客户端组件Eureka Client,它使与服务的交互变得更加容易。客户端还具有一个内置的负载平衡器,可以执行基本的循环负载平衡。在Netflix,更复杂的负载均衡器将Eureka包装起来,以基于流量,资源使用,错误条件等多种因素提供加权负载均衡,以提供出色的弹性。
总的来说,Eureka 就是一个服务发现框架。何为服务,何又为发现呢?
举一个生活中的例子,就比如我们平时租房子找中介的事情。
在没有中介的时候我们需要一个一个去寻找是否有房屋要出租的房东,这显然会非常的费力,一你找凭一个人的能力是找不到很多房源供你选择,再者你也懒得这么找下去(找了这么久,没有合适的只能将就)。这里的我们就相当于微服务中的 Consumer ,而那些房东就相当于微服务中的 **Provider **。消费者 Consumer 需要调用提供者 Provider 提供的一些服务,就像我们现在需要租他们的房子一样。
角色
服务提供者: 就是提供一些自己能够执行的一些服务给外界。
服务消费者: 就是需要使用一些服务的“用户”。
服务中介: 其实就是服务提供者和服务消费者之间的“桥梁”,服务提供者可以把自己注册到服务中介那里,而服务消费者如需要消费一些服务(使用一些功能)就可以在服务中介中寻找注册在服务中介的服务提供者。
可以充当服务发现的组件有很多:Zookeeper ,Consul , Eureka 等。
基础概念
-
服务注册 Register:当
Eureka客户端向Eureka Server注册时,它提供自身的元数据,比如IP地址、端口,运行状况指示符URL,主页等。 -
服务续约 Renew:
Eureka客户会每隔30秒(默认情况下)发送一次心跳来续约。 通过续约来告知Eureka Server该Eureka客户仍然存在,没有出现问题。 正常情况下,如果Eureka Server在90秒没有收到Eureka客户的续约,它会将实例从其注册表中删除。 -
获取注册列表信息 Fetch Registries:
Eureka客户端从服务器获取注册表信息,并将其缓存在本地。客户端会使用该信息查找其他服务,从而进行远程调用。该注册列表信息定期(每30秒钟)更新一次。每次返回注册列表信息可能与Eureka客户端的缓存信息不同,Eureka客户端自动处理。如果由于某种原因导致注册列表信息不能及时匹配,Eureka客户端则会重新获取整个注册表信息。Eureka服务器缓存注册列表信息,整个注册表以及每个应用程序的信息进行了压缩,压缩内容和没有压缩的内容完全相同。Eureka客户端和Eureka服务器可以使用JSON / XML格式进行通讯。在默认的情况下Eureka客户端使用压缩JSON格式来获取注册列表的信息。 -
服务下线 Cancel:Eureka客户端在程序关闭时向Eureka服务器发送取消请求。 发送请求后,该客户端实例信息将从服务器的实例注册表中删除。该下线请求不会自动完成,它需要调用以下内容:
DiscoveryManager.getInstance().shutdownComponent(); -
服务剔除 Eviction: 在默认的情况下,当Eureka客户端连续90秒(3个续约周期)没有向Eureka服务器发送服务续约,即心跳,Eureka服务器会将该服务实例从服务注册列表删除,即服务剔除。
Eureka架构

蓝色的 Eureka Server 是 Eureka 服务器,这三个代表的是集群,而且他们是去中心化的。
绿色的 Application Client 是 Eureka 客户端,其中可以是消费者和提供者,最左边的就是典型的提供者,它需要向 Eureka 服务器注册自己和发送心跳包进行续约,而其他消费者则通过 Eureka 服务器来获取提供者的信息以调用他们
Eureka 与 Zookeeper 对比
- Eureka: 符合AP原则 为了保证了可用性,
Eureka不会等待集群所有节点都已同步信息完成,它会无时无刻提供服务。 - Zookeeper: 符合CP原则 为了保证一致性,在所有节点同步完成之前是阻塞状态的。
创建EurekaServer
首先创建一个Maven工程,我们之后所有的SpringCloud组件都将在这个Maven中创建和完善
在Maven工程中新建一个SpringBoot项目,其中我们勾选Spring Cloud DisCovery中的Eureka依赖
我们在SpringBoot启动类上加上注解@EnableEurekaServer,表示启动Eureka服务
1 |
|
最后在配置文件中配置
1 | #单机版 |
完成配置后我们只需启动服务即可,访问端口1111,就会看到eureka的首页
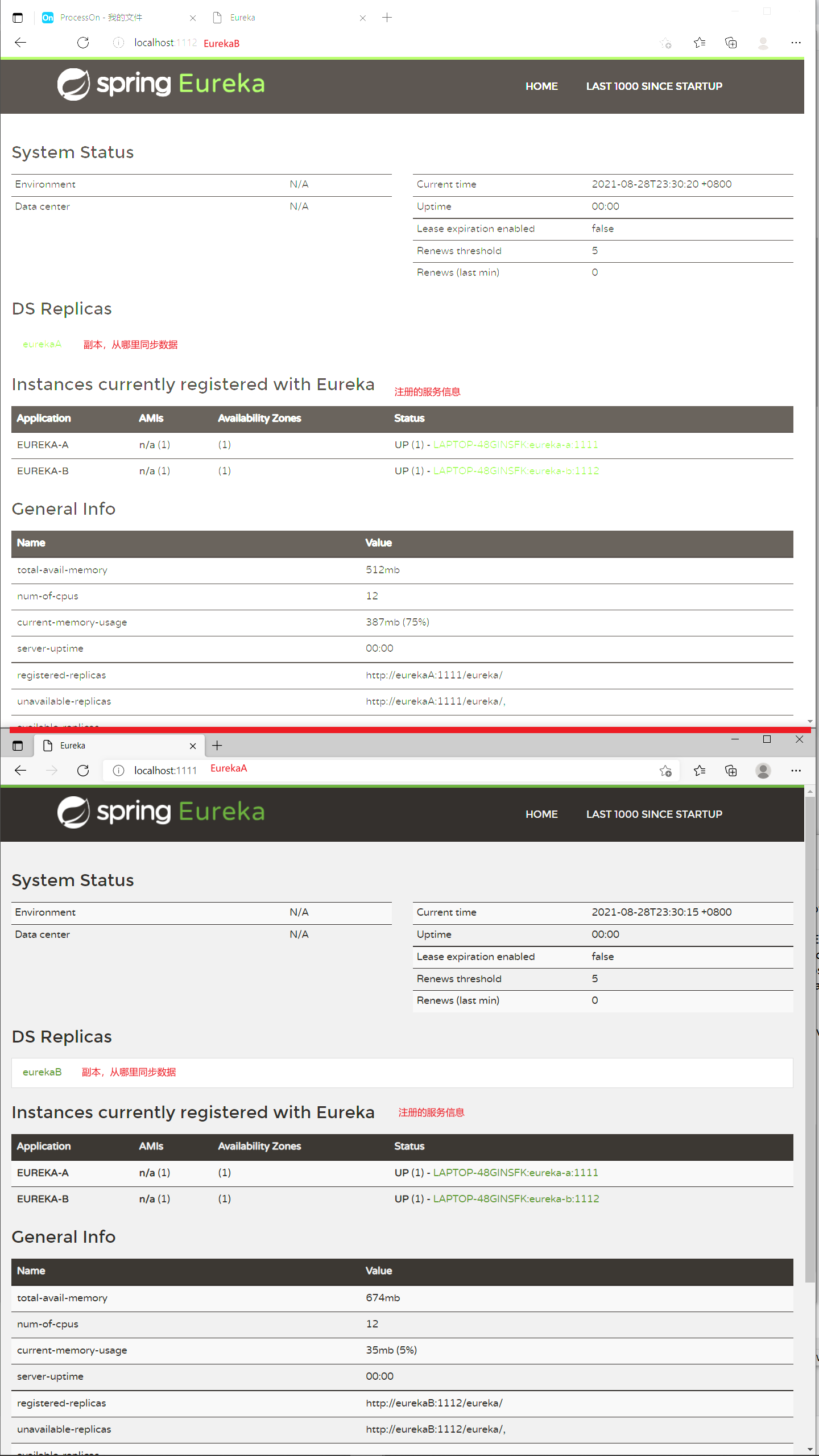
首页信息如下

Eureka集群
使用了注册中心之后,所有的服务都要通过服务注册中心来进行信息交换。服务注册中心的稳定性就非常重要了,一旦服务注册中心掉线,会影响到整个系统的稳定性。所以,在实际开发中,Eureka 一般都是以集群的形式出现的。
Eureka 集群,实际上就是启动多个 Eureka 实例,多个 Eureka 实例之间,互相注册,互相同步数据,共同组成一个 Eureka 集群。
前面单机的时候 eureka注册中心实例名称 是localhost,现在是集群,不能三个实例都是localhost,这里复杂的办法是搞三个虚拟机,麻烦,这里有简单办法,直接配置本机hosts,来实现本机域名映射;
找到 C:\Windows\System32\drivers\etc 打开hosts,加配置

我们修改一下配置文件
application-a.properties
1 | #集群版 |
application-b.properties
1 | #集群版 |
我们将服务打成jar包分别启动注册中心A和注册中心B
然后我们分别访问1111和1112即可
创建EurekaClient
Provider
Proivder供应者
创建SpringBoot项目时,勾选Web依赖和一个Eureka Discovery Client依赖

-
在启动类上加上
@EnableEurekaClient
-
书写配置文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21#消费者服务
#端口
=8080
#服务名称
=provider-application
#实例名称
=provider
#注册到eureka
=true
#从eureka拉取服务列表信息
=true
#注册中心
=http://localhost:1111/eureka
=true -
书写一个接口
1
2
3
4
5
6
7
8
9
10
11
12
public class ProviderController {
Integer port;
public String hello( String name){
return "hello,Consumer"+name+",来自Provider:"+port+"的问候";
}
}
Consumer
Consumer消费者
创建SpringBoot项目时,勾选Web依赖和一个Eureka Discovery Client依赖

-
在启动类上加上
@EnableEurekaClient
-
书写配置文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21#消费者服务
#端口
=8081
#服务名称
=consumer-application
#实例名称
=consumer
#注册到eureka
=true
#从eureka拉取服务列表信息
=true
#注册中心
=http://localhost:1111/eureka
=true -
接口一
使用固定ip形式,充分体现了,注册中心的重要性
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37/**
* @program: demo
* @description:
* @author: xpp011
* @create: 2021-08-29 17:09
**/
public class ConsumerController {
/**
* 不使用eureka提供的服务列表信息,主要先凸显一下注册中心的好处
* @return
*/
public String hello1( String name){
HttpURLConnection con=null;
try {
//注意这里的url是写死的,也就意味着一旦提供服务的服务ip或者端口发生变化,就会波及到当前服务
//需要修改这里的ip或者端口
URL url=new URL("http://localhost:8080/provider/"+name);
con = (HttpURLConnection) url.openConnection();
if (con.getResponseCode()==200) {
BufferedReader stream=new BufferedReader(new InputStreamReader(con.getInputStream()));
return stream.readLine();
}
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return "error";
}
....
} -
接口二
实现了从注册中心拉取服务信息列表
动态的修改供应者服务ip以及端口号
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48/**
* @program: demo
* @description:
* @author: xpp011
* @create: 2021-08-29 17:09
**/
public class ConsumerController {
...
private DiscoveryClient discoveryClient;
/**
* 使用eureka提供的discoveryClient来获取服务列表信息
* 从而动态的获取服务的ip和端口
* @param name
* @return
*/
public String hello2( String name){
//根据服务名称获取服务的实例列表
//由于同一个服务模块有个服务,也即是集群部署 所以返回值为list
List<ServiceInstance> instances = discoveryClient.getInstances("PROVIDER-APPLICATION");
ServiceInstance serviceInstance = instances.get(0);
URI uri = serviceInstance.getUri();
HttpURLConnection con=null;
try {
URL url=new URL(uri+"/provider/"+name);
con = (HttpURLConnection) url.openConnection();
if (con.getResponseCode()==200) {
BufferedReader stream=new BufferedReader(new InputStreamReader(con.getInputStream()));
return stream.readLine();
}
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return "error";
}
...
} -
接口三
-
将Provider的jar包启动两个,注意修改第二个Provider的实例名称,不然两个重名在eureka上不显示
$ java -jar Provider-0.0.1-SNAPSHOT.jar --server.por
t=8082 --eureka.instance.instance-id=provider2简单实现负载均衡
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43/**
* @program: demo
* @description:
* @author: xpp011
* @create: 2021-08-29 17:09
**/
public class ConsumerController {
...
/**
* 简单实现线性负载均衡
* @param name
* @return
*/
int count=0;
public String hello3( String name){
//获取服务的实例列表
//由于同一个服务模块有个服务,也即是集群部署 所以返回值为list
List<ServiceInstance> instances = discoveryClient.getInstances("PROVIDER-APPLICATION");
ServiceInstance serviceInstance = instances.get(count++%instances.size());
URI uri = serviceInstance.getUri();
HttpURLConnection con=null;
try {
URL url=new URL(uri+"/provider/"+name);
con = (HttpURLConnection) url.openConnection();
if (con.getResponseCode()==200) {
BufferedReader stream=new BufferedReader(new InputStreamReader(con.getInputStream()));
return stream.readLine();
}
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return "error";
}
} -
-
接口四
通过一个支持
Ribbon功能的RestTemplate调用请求Ribbon简介
Spring Cloud Ribbon是一个基于HTTP和TCP的客户端负载均衡工具,它基于Netflix Ribbon实现。通过Spring Cloud的封装,可以让我们轻松地将面向服务的REST模版请求自动转换成客户端负载均衡的服务调用。Spring Cloud Ribbon虽然只是一个工具类框架,它不像服务注册中心、配置中心、API网关那样需要独立部署,但是它几乎存在于每一个Spring Cloud构建的微服务和基础设施中。因为微服务间的调用,API网关的请求转发等内容,实际上都是通过Ribbon来实现的,包括后续我们将要介绍的Feign,它也是基于Ribbon实现的工具。所以,对Spring Cloud Ribbon的理解和使用,对于我们使用Spring Cloud来构建微服务非常重要。
我们可以通过注解
@LoadBalanced获取一个具有Ribbon功能的RestTemplateRestTemplate使用手册
1 |
|
然后我们就可以极其方便的调用其他服务请求
1 |
|
最后我们看一下eureka所展示的页面

客户端负载均衡Ribbon
-
什么是 RestTemplate?
不是讲 Ribbon 么?怎么扯到了 RestTemplate 了?你先别急,听我慢慢道来。
我不听我不听我不听 。
我就说一句!RestTemplate是Spring提供的一个访问Http服务的客户端类,怎么说呢?就是微服务之间的调用是使用的 RestTemplate 。比如这个时候我们 消费者B 需要调用 提供者A 所提供的服务我们就需要这么写。如我下面的伪代码。
1 |
|
如果你对源码感兴趣的话,你会发现上面我们所讲的 Eureka 框架中的 注册、续约 等,底层都是使用的 RestTemplate 。
-
为什么需要 Ribbon?
Ribbon 是 Netflix 公司的一个开源的负载均衡 项目,是一个客户端/进程内负载均衡器,运行在消费者端。
我们再举个 ,比如我们设计了一个秒杀系统,但是为了整个系统的 高可用 ,我们需要将这个系统做一个集群,而这个时候我们消费者就可以拥有多个秒杀系统的调用途径了,如下图。

如果这个时候我们没有进行一些 均衡操作 ,如果我们对 秒杀系统1 进行大量的调用,而另外两个基本不请求,就会导致 秒杀系统1 崩溃,而另外两个就变成了傀儡,那么我们为什么还要做集群,我们高可用体现的意义又在哪呢?
所以 Ribbon 出现了,注意我们上面加粗的几个字——运行在消费者端。指的是,Ribbon 是运行在消费者端的负载均衡器,如下图。

其工作原理就是 Consumer 端获取到了所有的服务列表之后,在其内部使用负载均衡算法,进行对多个系统的调用。
-
Nginx 和 Ribbon 的对比
提到 负载均衡 就不得不提到大名鼎鼎的 Nignx 了,而和 Ribbon 不同的是,它是一种集中式的负载均衡器。
何为集中式呢?简单理解就是 将所有请求都集中起来,然后再进行负载均衡。如下图。
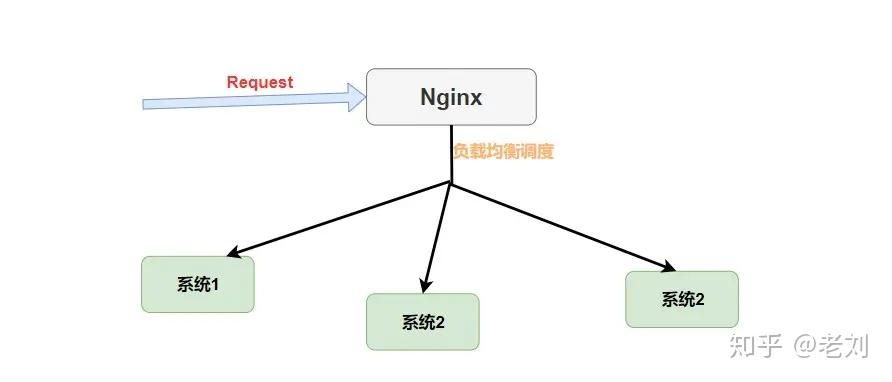
我们可以看到 Nginx 是接收了所有的请求进行负载均衡的,而对于 Ribbon 来说它是在消费者端进行的负载均衡。如下图。

请注意
Request的位置,在Nginx中请求是先进入负载均衡器,而在Ribbon中是先在客户端进行负载均衡才进行请求的。
-
Ribbon 的几种负载均衡算法
负载均衡,不管 Nginx 还是 Ribbon 都需要其算法的支持,如果我没记错的话 Nginx 使用的是 轮询和加权轮询算法。而在 Ribbon 中有更多的负载均衡调度算法,其默认是使用的 RoundRobinRule 轮询策略。
- RoundRobinRule:轮询策略。
Ribbon默认采用的策略。若经过一轮轮询没有找到可用的provider,其最多轮询 10 轮。若最终还没有找到,则返回 null。 - RandomRule: 随机策略,从所有可用的 provider 中随机选择一个。
- RetryRule: 重试策略。先按照 RoundRobinRule 策略获取 provider,若获取失败,则在指定的时限内重试。默认的时限为 500 毫秒。
还有很多,这里不一一举 了,你最需要知道的是默认轮询算法,并且可以更换默认的负载均衡算法,只需要在配置文件中做出修改就行。
1 | providerName: |
当然,在 Ribbon 中你还可以自定义负载均衡算法,你只需要实现 IRule 接口,然后修改配置文件或者自定义 Java Config 类。
-
Ribbon原理概述(背下来)
通过源码分析,个人认为可以拆解为如下部分:
- 获取
@LoadBalanced注解标记的RestTemplate。 RestTemplate添加一个拦截器(filter),当使用RestTemplate发起http调用时进行拦截。- 在filter拦截到该请求时,获取该次请求服务集群的全部列表信息。
- 根据规则从集群中选取一个服务作为此次请求访问的目标。
- 将
originalURI的服务名称通过reconstructURI()方法解析为可访问的IP和端口 - 访问该目标,并获取返回结果。
Ribbon现在以及是SpringCloud自带的负载均衡服务了
四,Ribbon源码解析
Ribbon源码解析参考链接 (版本有些老了,和新版代码有些冲突)
简介
Spring cloud ribbon在spring cloud微服务体系中充当着负载均衡的角色。这个负载均衡指的是客户端的负载均衡。本文是ribbon源码分析系列的第一篇,主要内容如下:
- 怎样使用spring cloud ribbon
- ribbon原理概览
怎样使用Spring cloud ribbon
我们知道ribbon是客户端负载均衡,也就是说在相同的服务集群中选择一个,然后进行访问,并从该服务获取到结果。这里面会引申出一个问题,就是相同服务集群的来源。ribbon有两种方式获取,第一种是通过Eureka(注册中心),这种方式需要使用ribbon的工程是一个Eureka Client也就是说需要在工程的主函数上使用(@EnableDiscoveryClient),第二种方式是通过properties进行配置。
本文主要介绍的是第二种。
下面结合一个例子来说明:
添加对应依赖
1 | <dependency> |
定义配置类
1 |
|
如上图所示在该配置类中创建RestTemplate,并且使用@LoadBalanced注解。该注解使得RestTemplate具有了客户端负载均衡的能力。
properties文件
1 | spring.application.name=ribbon-client |
定义一个Controller(Ribbon-Client端)
1 |
|
后端Server代码(8081、8082)
1 |
|
1 |
|
此时当我们访问[http://localhost:8080/ribbon并且不断刷新浏览器(多次访问该接口),我们可以看到http://localhost:8081/hello、http://localhost:8082/hello这两个接口反复被调用。(交替返回)
至此通过这个例子我们完成了使用ribbon来完成客户端负载均衡的功能,接下来通过源码了解下其中的原理。
Ribbon原理概览
通过源码分析,个人认为可以拆解为如下部分:
- 获取
@LoadBalanced注解标记的RestTemplate。 RestTemplate添加一个拦截器(filter),当使用RestTemplate发起http调用时进行拦截。- 在filter拦截到该请求时,获取该次请求服务集群的全部列表信息。
- 根据规则从集群中选取一个服务作为此次请求访问的目标。
- 将
originalURI的服务名称通过reconstructURI()方法解析为可访问的IP和端口 - 访问该目标,并获取返回结果。
获取@LoadBalanced注解标记的RestTemplate。
Ribbon将所有标记@LoadBalanced注解的RestTemplate保存到一个List集合当中,具体源码如下:
1 |
|
具体源码位置是在LoadBalancerAutoConfiguration中。
RestTemplate添加一个拦截器(filter)
RestTemplate添加拦截器需要有两个步骤,首先是定义一个拦截器,其次是将定义的拦截器添加到RestTemplate中。
定义一个拦截器
实现ClientHttpRequestInterceptor接口就具备了拦截请求的功能,该接口源码如下:
1 | public interface ClientHttpRequestInterceptor { |
ribbon中对应的实现类是LoadBalancerInterceptor(不使用spring-retry的情况下)具体源码如下:
1 | public class LoadBalancerInterceptor implements ClientHttpRequestInterceptor { |
将拦截器添加到RestTemplate中
RestTemplate继承了InterceptingHttpAccessor,在InterceptingHttpAccessor中提供了获取以及添加拦截器的方法,具体源码如下:
1 | public abstract class InterceptingHttpAccessor extends HttpAccessor { |
通过这两个方法我们就可以将刚才定义的LoadBalancerInterceptor添加到有@LoadBalanced注解标识的RestTemplate中。具体的源码如下(LoadBalancerAutoConfiguration)省略部分代码:
1 | public class LoadBalancerAutoConfiguration { |
至此知道了ribbon拦截请求的基本原理,接下来我们看看Ribbon是怎样选取server的。
Ribbon选取server原理概览
通过上面的介绍我们知道了当发起请求时ribbon会用LoadBalancerInterceptor这个拦截器进行拦截。并在接口LoadBalancerClient的实现类BlockingLoadBalancerClient.execute()该方法具体代码如下:
1 |
|
通过代码我们可知,首先创建一个ILoadBalancer,这个ILoadBalancer是Ribbon的核心类。可以理解成它包含了选取服务的规则(IRule)、服务集群的列表(ServerList)、检验服务是否存活(IPing)等特性,同时它也具有了根据这些特性从服务集群中选取具体一个服务的能力。
Server server = getServer(loadBalancer);这行代码就是选取举一个具体server。
最终调用了内部的execute方法,该方法代码如下(只保留了核心代码):
1 |
|
接下来看下request.apply(serviceInstance)方法的具体做了那些事情(LoadBalancerRequestFactory中):
1 |
|
看到这里整体流程的原理就说完了,接下来我们结合一张图来回顾下整个过程:

首先获取所有标识@LoadBalanced注解的RestTemplate(可以理解成获取那些开启了Ribbon负载均衡功能的RestTemplate),然后将Ribbon默认的拦截器LoadBalancerInterceptor添加到RestTemplate中,这样当使用RestTemplate发起http请求时就会起到拦截的作用。当有请求发起时,ribbon默认的拦截器首先会创建ILoadBalancer(里面包含了选取服务的规则(IRule)、服务集群的列表(ServerList)、检验服务是否存活(IPing)等特性)。在代码层面的含义是加载RibbonClientConfiguration配置类)。然后使用ILoadBalancer从服务集群中选择一个服务,最后向这个服务发送请求。
五,Consul
简介
Consul 是 HashiCorp 公司推出的开源产品,用于实现分布式系统的服务发现、服务隔离、服务配置,这些功能中的每一个都可以根据需要单独使用,也可以同时使用所有功能。Consul 官网目前主要推 Consul 在服务网格中的使用。
与其它分布式服务注册与发现的方案相比,Consul 的方案更“一站式”——内置了服务注册与发现框架、分布一致性协议实现、健康检查、Key/Value 存储、多数据中心方案,不再需要依赖其它工具。Consul 本身使用 go 语言开发,具有跨平台、运行高效等特点,也非常方便和 Docker 配合使用。
Consul 的主要特点有:
-
Service Discovery :
服务注册与发现,Consul 的客户端可以做为一个服务注册到 Consul,也可以通过 Consul 来查找特定的服务提供者,并且根据提供的信息进行调用。
-
Health Checking:
Consul 客户端会定期发送一些健康检查数据和服务端进行通讯,判断客户端的状态、内存使用情况是否正常,用来监控整个集群的状态,防止服务转发到故障的服务上面。
-
KV Store:
Consul 还提供了一个容易使用的键值存储。这可以用来保持动态配置,协助服务协调、建立 Leader 选举,以及开发者想构造的其它一些事务。
-
Secure Service Communication:
Consul 可以为服务生成分布式的 TLS 证书,以建立相互的 TLS 连接。 可以使用 intentions 定义允许哪些服务进行通信。 可以使用 intentions 轻松管理服务隔离,而不是使用复杂的网络拓扑和静态防火墙规则。
-
Multi Datacenter:
Consul 支持开箱即用的多数据中心,这意味着用户不需要担心需要建立额外的抽象层让业务扩展到多个区域。
Consul 角色:
-
Server: 服务端, 保存配置信息, 高可用集群, 在局域网内与本地客户端通讯, 通过广域网与其它数据中心通讯。 每个数据中心的 Server 数量推荐为 3 个或是 5 个。
-
Client: 客户端, 无状态, 将 HTTP 和 DNS 接口请求转发给局域网内的服务端集群。
Consul 旨在对 DevOps 社区和应用程序开发人员友好,使其成为现代、弹性基础架构的理想选择。
使用Consul 的优势
使用 Raft 算法来保证一致性, 比复杂的 Paxos 算法更直接。相比较而言, zookeeper 采用的是 Paxos, 而 etcd 使用的则是 Raft。
支持多数据中心,内外网的服务采用不同的端口进行监听。多数据中心集群可以避免单数据中心的单点故障,而其部署则需要考虑网络延迟, 分片等情况等。 zookeeper 和 etcd 均不提供多数据中心功能的支持。
支持健康检查。 etcd 不提供此功能。
支持 http 和 dns 协议接口。 zookeeper 的集成较为复杂, etcd 只支持 http 协议。
官方提供 Web 管理界面, etcd 无此功能。
Consul 保持了 CAP 中的 CP,保持了强一致性和分区容错性。
Consul 支持 Http\gRPC\DNS 多种访问方式。
Consul 的调用过程
首先我们根据一张图来了解一下 Consul 服务调用过程:

1、当 Producer 启动的时候,会向 Consul 发送一个 post 请求,告诉 Consul 自己的 IP 和 Port;
2、Consul 接收到 Producer 的注册后,每隔 10s(默认)会向 Producer 发送一个健康检查的请求,检验 Producer 是否健康;
3、当 Consumer 发送 GET 方式请求 /api/address 到 Producer 时,会先从 Consul 中拿到一个存储服务 IP 和 Port 的临时表,从表中拿到 Producer 的 IP 和 Port 后再发送 GET 方式请求 /api/address;
4、该临时表每隔 10s 会更新,只包含有通过了健康检查的 Producer。
Spring Cloud Consul 项目是针对 Consul 的服务治理实现。Consul 是一个分布式高可用的系统,它包含多个组件,但是作为一个整体,在微服务架构中,为我们的基础设施提供服务发现和服务配置的工具。
Consul 和 eureka的对比
我们先来通过一个表格做简单对比
| Feature | Euerka | Consul |
|---|---|---|
| 服务健康检查 | 可配支持 | 服务状态,内存,硬盘等 |
| 多数据中心 | — | 支持 |
| kv 存储服务 | — | 支持 |
| 一致性 | — | raft |
| cap | ap | cp |
| 使用接口(多语言能力) | http(sidecar) | 支持 http 和 dns |
| watch 支持 | 支持 long polling/大部分增量 | 全量/支持long polling |
| 自身监控 | metrics | metrics |
| 安全 | — | acl /https |
| 编程语言 | Java | go |
| Spring Cloud 集成 | 已支持 | 已支持 |
通过对比可以得知, Consul 功能更强大,Euerka 更容易使用。
Consul 强一致性©带来的是:
服务注册相比 Eureka 会稍慢一些。因为 Consul 的 raft 协议要求必须过半数的节点都写入成功才认为注册成功,。Leader 挂掉时,重新选举期间整个 Consul 不可用。保证了强一致性但牺牲了可用性。
Consul 强烈的一致性意味着它可以作为领导选举和集群协调的锁定服务。
Eureka 保证高可用(A)和最终一致性:
服务注册相对要快,因为不需要等注册信息 replicate 到其它节点,也不保证注册信息是否 replicate 成功。当数据出现不一致时,虽然 A, B 上的注册信息不完全相同,但每个 Eureka 节点依然能够正常对外提供服务,这会出现查询服务信息时如果请求 A 查不到,但请求 B 就能查到。如此保证了可用性但牺牲了一致性。
安装
windows安装
Consul 不同于 Eureka 是由 go 语言开发而成,因此需要我们单独来安装。
打开 Consul官网根据不同的操作系统选择最新的 Consul 版本,我们这里以 Windows 64 操作系统为例,可以看出 Consul 目前的最新版本为 1.10.2

下载下来是一个 consul_1.4.4_windows_amd64.zip 的压缩包,解压是一个 consul.exe 的执行文件。

cd 到对应的目录下,使用 cmd 启动 Consul:
cd D:\Common Files\consul
#cmd启动: consul agent -dev # -dev表示开发模式运行,另外还有-server表示服务模式运行
为了方便启动,可以在同级目录下创建一个 run.bat 脚本来启动,脚本内容如下:
@echo off
rem -dev开发模式启动 -server服务器启动
consul agent -dev
下次启动的时候直接双击 run.bat 文件即可;当然也可以把 consul 的 exe 文件路径加入到本机的 path 路径下,这样后期只需要在 cmd 命令行下运行
执行命令后,命令行会输出如下信息:

启动成功之后访问:localhost:8500,就可以看到Consul的管理界面

Consul 的 Web 管理界面有一些菜单,我们这里做一下简单的介绍:
-
Services
管理界面的默认页面,用来展示注册到 Consul 的服务,启动后默认会有一个 consul 服务,也就是它本身。
-
Nodes
在 Services 界面双击服务名就会来到 Services 对于的 Nodes 界面,Services 是按照服务的抽象来展示的,Nodes 展示的是此服务的具体节点信息。比如启动了两个订单服务实例,Services 界面会出现一个订单服务,Nodes 界面会展示两个订单服务的节点。
-
Key/Value
如果有用到 Key/Value 存储,可以在界面进行配置、查询。
-
Intentions
可以在页面配置请求权限。
当我们看到这个页面后,也就意味着 Consul 已经安装成功了。
Linux安装
下载Consul
sudo wget https://releases.hashicorp.com/consul/1.10.2/consul_1.10.2_linux_amd64.zip
解压Consul.zip文件
sudo unzip consul_1.10.2_linux_amd64.zip
启动
-dev表示开发环境允许 -node后面则是consul的名称
./consul agent -dev -ui -node=consul-dev -client=192.168.32.131

此时我们的注册中心就创建好了(Consul是一个独立的服务)
注册服务
创建一个SpringBoot工程
加入以下依赖
- Spring Web
- Consul Discovery
- Spring Boot Actuator
由于Consul具有服务健康检查功能,所以我们需要加入Spring Boot Actuator依赖,将该服务的健康信息加载到Consul中
Spring boot actuator介绍
Spring Boot包含许多其他功能,可帮助您在将应用程序推送到生产环境时监视和管理应用程序。
您可以选择使用HTTP端点或JMX来管理和监视应用程序。
审核,运行状况和指标收集也可以自动应用于您的应用程序。
总之Spring Boot Actuator就是一款可以帮助你监控系统数据的框架,其可以监控很多很多的系统数据,它有对应用系统的自省和监控的集成功能,可以查看应用配置的详细信息,如:
-
显示应用程序员的Health健康信息
-
显示Info应用信息
-
显示HTTP Request跟踪信息
-
显示当前应用程序的“Metrics”信息
-
显示所有的@RequestMapping的路径信息
-
显示应用程序的各种配置信息
-
显示你的程序请求的次数 时间 等各种信息

properties配置信息
1 | #服务名称 |
在启动类中加入@EnableDiscoveryClient注解

集群版
Provider
只需启动两个provider即可
java -jar Consul-Provider-0.0.1-SNAPSHOT.ja
r --server.port=6666 --spring.cloud.consul.discovery.instance-id=provider2

Consumer
Consumer的创建方式和Provider方式一样
不做过多赘述
我们来直接看负载均衡调用
创建一个带负载均衡RestTemplat的Bean
1 |
|
发起调用
1 |
|
Ribbon现在以及是SpringCloud自带的负载均衡服务了
Ribbon的负载均衡原理请看四,Ribbon源码解析
六,Hystrix
Hystrix是什么
在分布式环境中,许多服务依赖项中的一些必然会失败。Hystrix是一个库,通过添加延迟容忍和容错逻辑,帮助你控制这些分布式服务之间的交互。Hystrix通过隔离服务之间的访问点、停止级联失败和提供回退选项来实现这一点,所有这些都可以提高系统的整体弹性。
Hystrix为了什么
Hystrix被设计的目标是:
- 对通过第三方客户端库访问的依赖项(通常是通过网络)的延迟和故障进行保护和控制。
- 在复杂的分布式系统中阻止级联故障。
- 快速失败,快速恢复。
- 回退,尽可能优雅地降级。
- 启用近实时监控、警报和操作控制。
Hystrix解决了什么问题
复杂分布式体系结构中的应用程序有许多依赖项,每个依赖项在某些时候都不可避免地会失败。如果主机应用程序没有与这些外部故障隔离,那么它有可能被他们拖垮。
例如,对于一个依赖于30个服务的应用程序,每个服务都有99.99%的正常运行时间,你可以期望如下:
99.9930 = 99.7% 可用
也就是说一亿个请求的0.03% = 3000000 会失败
如果一切正常,那么每个月有2个小时服务是不可用的
现实通常是更糟糕
当一切正常时,请求看起来是这样的:

当其中有一个系统有延迟时,它可能阻塞整个用户请求:

在高流量的情况下,一个后端依赖项的延迟可能导致所有服务器上的所有资源在数秒内饱和(PS:意味着后续再有请求将无法立即提供服务)

Hystrix设计原则是什么
- 防止任何单个依赖项耗尽所有容器(如Tomcat)用户线程。
- 甩掉包袱,快速失败而不是排队。
- 在任何可行的地方提供回退,以保护用户不受失败的影响。
- 使用隔离技术(如隔离板、泳道和断路器模式)来限制任何一个依赖项的影响。
- 通过近实时的度量、监视和警报来优化发现时间。
- 通过配置的低延迟传播来优化恢复时间。
- 支持对Hystrix的大多数方面的动态属性更改,允许使用低延迟反馈循环进行实时操作修改。
- 避免在整个依赖客户端执行中出现故障,而不仅仅是在网络流量中。
Hystrix是如何实现它的目标的
- 用一个HystrixCommand 或者 HystrixObservableCommand (这是命令模式的一个例子)包装所有的对外部系统(或者依赖)的调用,典型地它们在一个单独的线程中执行
- 调用超时时间比你自己定义的阈值要长。有一个默认值,对于大多数的依赖项你是可以自定义超时时间的。
- 为每个依赖项维护一个小的线程池(或信号量);如果线程池满了,那么该依赖性将会立即拒绝请求,而不是排队。
- 调用的结果有这么几种:成功、失败(客户端抛出异常)、超时、拒绝。
- 在一段时间内,如果服务的错误百分比超过了一个阈值,就会触发一个断路器来停止对特定服务的所有请求,无论是手动的还是自动的。
- 当请求失败、被拒绝、超时或短路时,执行回退逻辑。
- 近实时监控指标和配置变化。
当你使用Hystrix来包装每个依赖项时,上图中所示的架构会发生变化,如下图所示:
每个依赖项相互隔离,当延迟发生时,它会被限制在资源中,并包含回退逻辑,该逻辑决定在依赖项中发生任何类型的故障时应作出何种响应:

八,OpenFeign
简介
OpenFeign是一种声明式、模板化的HTTP客户端。在Spring Cloud中使用OpenFeign,可以做到使用HTTP请求访问远程服务,就像调用本地方法一样的,开发者完全感知不到这是在调用远程方法,更感知不到在访问HTTP请求
构建OpenFigen应用

配置文件
主要配置Eureka信息
注意eurekaA已在本地host文件中映射到1270.0.1
1 | spring.application.name=OpenFeignServer |
-
在启动类中加入
@EnableEurekaClient和@EnableFeignClients@EnableFeignClients申明该项目是Feign客户端,扫描对应的feign client。@EnableEurekaClient申明该项目是Eureka客户端,将注册到Eureka和拉取注册中心信息
1
2
3
4
5
6
7
public class OpenFeignApplication {
public static void main(String[] args) {
SpringApplication.run(OpenFeignApplication.class, args);
}}
-
书写API接口
我们需要集中化管理API,就可以通过接口统一管理,需要新增提供者(Provdier)服务的接口,并添加
@FeignClient(name="PROVIDER-APPLICATION")注解,其中name就是我们要访问的微服务的名称。比如hello方法中@GetMapping("/hello")和服务提供者的hello的接口路径是一样的1
2
3
4
5
6
7
8
9
10//和注册中心的服务绑定
public interface HelloService {
//服务的接口名称以及请求方式
//接口返回类型
String hello();
}
不难发现使用OpenFegin调用接口更加方便,相较于使用RestTemplate,更加水到渠成,符合条理
最后我们在Controller层调用OpenFeign的接口
1 |
|
所有请求方式的案例
- Controller(Consumer)
1 |
|
- OpenFeign接口(Consumer)
1 | //和注册中心的服务绑定 |
- API接口(Provider)
1 |
|
值得注意的是OpenFeign接口
凡是key/value形式的参数全部需要加上@RequestParam("参数名称") || @PathVariable("参数名称")
JSON数据加上@RequestBody注解
继承特性
继承特性主体思想就是将接口提取成为一个模块,并在Provider模块和Consumer模块中继承接口模块,这样方便了接口的统一,在修改过程中不需要在去Provider模块和Consumer模块的接口,而是修改接口模块
缺点也显而易见,在分布式服务中,我们致力于将服务之间的耦合度降到最低,而实现继承特性,无疑增加了耦合度。
创建接口模块
- 创建Maven模块(方引用)

- 在pom.xml文件中引入Web依赖(需要
@XXXMapping接口)和Commons依赖
1 |
|
-
在API模块中书写接口
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25public interface IUserService {
//服务的接口名称以及请求方式
//接口返回类型
String hello();
String hello( String name);
String name( String name);
String nameHeader( String name);
User addUser( User user);
User updateUser( User user);
Integer getAge( List<Integer> age);
} -
在
Provider模块Consumer模块中引入API模块1
2
3
4
5<dependency>
<groupId>cn.xpp011</groupId>
<artifactId>OpenFeign-API</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency> -
Provider模块的Controller实现API接口注意,由于接口中以及写了
@XXXMapping接口,所以Controller类中只需实现接口方法,不需要再写注解了
1 |
|
Consumer模块的OpenFeign接口只需继承API模块的接口即可
注意加上@FeignClient注解,于服务绑定
1 | //和注册中心的服务绑定 |
日志
OpenFeign中,我们可以使用日志来查看整个调用过程
级别
NONE:不开启日志BASIC:记录请求方法,URL,状态码,执行时间HEADERS:在BASIC基础上加上,响应头FULL:在HEADERS基础上,再增加body和请求元数据
首先我们需要再Bean中配置日志级别
1 |
|
最后在application.properties配置文件中指定包下的打印日志级别
logging.level.cn.xpp011=debug
以下就是OpenFeign打印的请求日志信息

数据压缩
数据压缩主要是将一些请求数据和响应数据过大时,进行数据压缩来提升传输效率
1 | #开启请求数据压缩 |
九,Resilience4j
官方文档: https://resilience4j.readme.io/
推荐文档:https://www.jianshu.com/p/5531b66b777a
简介
Resilience4j是一款轻量级,易于使用的容错库,其灵感来自于Netflix Hystrix,但是专为Java 8和函数式编程而设计。轻量级,因为库只使用了Vavr,它没有任何其他外部依赖下。相比之下,Netflix Hystrix对Archaius具有编译依赖性,Archaius具有更多的外部库依赖性,例如Guava和Apache Commons Configuration。
要使用Resilience4j,不需要引入所有依赖,只需要选择你需要的。
Resilience4j提供了以下的核心模块和拓展模块:
核心模块:
- resilience4j-circuitbreaker: Circuit breaking——断路器
- resilience4j-ratelimiter: Rate limiting——限流器
- resilience4j-bulkhead: Bulkheading
- resilience4j-retry: Automatic retrying (sync and async)——请求重试
- resilience4j-cache: Result caching
- resilience4j-timelimiter: Timeout handling
CircuitBreaker
简介
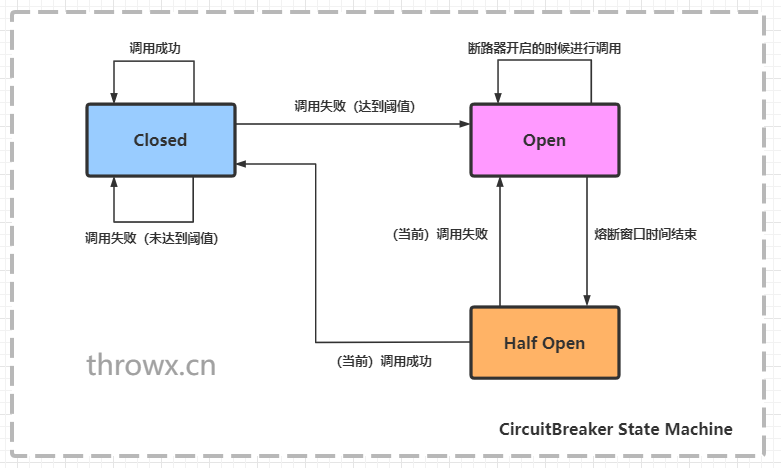
CircuitBreaker通过具有三种正常状态的有限状态机实现:CLOSED,OPEN和HALF_OPEN以及两个特殊状态DISABLED和FORCED_OPEN。当熔断器关闭时,所有的请求都会通过熔断器。如果失败率超过设定的阈值,熔断器就会从关闭状态转换到打开状态,这时所有的请求都会被拒绝。当经过一段时间后,熔断器会从打开状态转换到半开状态,这时仅有一定数量的请求会被放入,并重新计算失败率,如果失败率超过阈值,则变为打开状态,如果失败率低于阈值,则变为关闭状态。

Circuitbreaker状态机
Resilience4j记录请求状态的数据结构和Hystrix不同,Hystrix是使用滑动窗口来进行存储的,而Resilience4j采用的是Ring Bit Buffer(环形缓冲区)现CircuitBreajer继续使用了滑动窗口作为缓存器。Ring Bit Buffer在内部使用BitSet这样的数据结构来进行存储,BitSet的结构如下图所示:

环形缓冲区
每一次请求的成功或失败状态只占用一个bit位,与boolean数组相比更节省内存。BitSet使用long[]数组来存储这些数据,意味着16个值(64bit)的数组可以存储1024个调用状态。
计算失败率需要填满环形缓冲区。例如,如果环形缓冲区的大小为10,则必须至少请求满10次,才会进行故障率的计算,如果仅仅请求了9次,即使9个请求都失败,熔断器也不会打开。但是CLOSE*状态下的缓冲区大小设置为10并不意味着只会进入10*个 请求,在熔断器打开之前的所有请求都会被放入。
当故障率高于设定的阈值时,熔断器状态会从由CLOSE变为OPEN。这时所有的请求都会抛出CallNotPermittedException异常。当经过一段时间后,熔断器的状态会从OPEN变为HALF_OPEN,HALF_OPEN状态下同样会有一个Ring Bit Buffer,用来计算HALF_OPEN状态下的故障率,如果高于配置的阈值,会转换为OPEN,低于阈值则装换为CLOSE。与CLOSE状态下的缓冲区不同的地方在于,HALF_OPEN状态下的缓冲区大小会限制请求数,只有缓冲区大小的请求数会被放入。
除此以外,熔断器还会有两种特殊状态:DISABLED(始终允许访问)和FORCED_OPEN(始终拒绝访问)。这两个状态不会生成熔断器事件(除状态装换外),并且不会记录事件的成功或者失败。退出这两个状态的唯一方法是触发状态转换或者重置熔断器。
熔断器关于线程安全的保证措施有以下几个部分:
- 熔断器的状态使用AtomicReference保存的
- 更新熔断器状态是通过无状态的函数或者原子操作进行的
- 更新事件的状态用synchronized关键字保护
意味着同一时间只有一个线程能够修改熔断器状态或者记录事件的状态。
创建和配置断路器
您可以提供自己的自定义 断路器. 为了创建自定义全局 CircuitBreakerConfig,您可以使用 CircuitBreakerConfig 构建器。您可以使用构建器配置以下属性。CircuitBreakerConfig‘
| 配置属性 | 默认值 | 描述 |
|---|---|---|
| failureRateThreshold | 50 | 配置失败率阈值百分比。当故障率等于或大于阈值时,断路器切换到开路并开始短路呼叫。 |
| slowCallRateThreshold | 100 | 配置百分比阈值。当呼叫时长大于“slowCallDurationThreshold”时,CircuitBreaker认为该呼叫为慢速呼叫。当慢速呼叫的百分比大于等于该阈值时,CircuitBreaker会切换到开路,并开始短路呼叫。 |
| slowCallDurationThreshold | 60000 [ms] | 配置时长阈值,超过该阈值呼叫将被视为慢速呼叫,并提高慢速呼叫的速率。 |
| permittedNumberOfCalls InHalfOpenState | 10 | 当断路器半打开时,配置允许调用的数量。 |
| maxWaitDurationInHalfOpenState | 0 [ms] | 值0表示断路器将在半开状态无限等待,直到所有允许的调用完成。 |
| slidingWindowType | COUNT_BASED | 滑动窗口可以是基于计数的,也可以是基于时间的。如果滑动窗口是COUNT_BASED,则记录并聚合最后的’ slidingWindowSize ‘调用。如果滑动窗口是TIME_BASED,则记录并聚合最后一个’ slidingWindowSize '秒的调用。 |
| slidingWindowSize | 100 | 设置断路器关闭时记录通话结果的滑动窗口的大小。 |
| minimumNumberOfCalls | 100 | 配置CircuitBreaker在计算错误率或慢速呼叫率之前所需的最小呼叫数(每个滑动窗口周期)。例如,如果minimumNumberOfCalls为10,则必须至少记录10个呼叫,才能计算失败率。如果只有9个呼叫被记录,即使9个呼叫都失败了,断路器也不会切换到打开。 |
| waitDurationInOpenState | 60000 [ms] | 断路器从开路过渡到半开路所需的时间。 |
| automaticTransition FromOpenToHalfOpenEnabled | false | 如果设置为true,则意味着CircuitBreaker将自动从开状态过渡到半开状态,不需要调用来触发过渡。创建一个线程来监视CircuitBreakers的所有实例,一旦waitDurationInOpenState通过,就将它们转换到HALF_OPEN。然而,如果设置为false,则转换到HALF_OPEN只在调用时发生,即使在waitDurationInOpenState被传递之后。这样做的好处是没有线程监视所有断路器的状态。 |
| recordExceptions | empty | 记录为失败的异常列表,从而增加失败率。任何从列表中匹配或继承的异常都被视为失败,除非通过’ ignoreExceptions ‘显式忽略。如果你指定了一个异常列表,所有其他异常都算成功,除非它们被’ ignoreExceptions '显式忽略。 |
| ignoreExceptions | empty | 一列被忽略的例外,既不能算作失败也不能算作成功。任何从列表中匹配或继承的异常都不会被视为失败或成功,即使异常是’ recordexception '的一部分。 |
| recordFailurePredicate | throwable -> true 默认情况下,所有异常都记录为失败。 | 如果异常应该被记录为失败的定义谓词。如果异常应该被视为失败,则谓词必须返回true。谓词必须返回false,如果异常应该被视为成功,除非异常被“无知异常”显式地忽略。 |
| ignoreException | throwable -> false 默认情况下不忽略任何异常 | 一个定义谓词,如果一个异常应该被忽略,而不是被视为失败或成功。如果异常应该被忽略,则谓词必须返回true。如果异常应该被视为失败,则谓词必须返回false。 |
依赖
1 | <!-- https://mvnrepository.com/artifact/io.github.resilience4j/resilience4j-circuitbreaker --> |
java配置断路器
1 |
|
CircuitBreaker工具类
1 | public class CircuitBreakerUtil { |
控制台打印

AOP式调用CircuitBreaker
首先在连接器方法上使用**@CircuitBreaker(name=“”,fallbackMethod=“”)注解,其中name是要使用的熔断器的名称,fallbackMethod是要使用的降级方法,降级方法必须和原方法放在同一个类中,且降级方法的返回值需要和原方法相同,输入参数需要添加额外的exception**参数,类似这样:
1 | public RemoteServiceConnector{ |
实例测试代码
- provider接口
1 |
|
- OpenFeign接口
1 | /** |
- CircuitBreaker控制器
1 | /** |
- application.yml配置
1 | server: |
总结
-
失败率的计算必须等环装满才会计算
-
白名单优先级高于黑名单且白名单上的异常会被忽略,不会占用缓冲环位置,即不会计入失败率计算,但是会计入成功率计算(与文档不符,还需测验)
-
熔断器打开时同样会计算失败率,当状态转换为半开时重置为**-1**
-
只要出现异常都可以调用降级方法,不论是在白名单还是黑名单
-
熔断器的缓冲环有两个,一个关闭时的缓冲环,一个半打开时的缓冲环
-
熔断器关闭时,直至熔断器状态转换前所有请求都会通过,不会受到限制
-
熔断器半开时,限制请求数为缓冲环的大小,当调用次数满足
Half_Open缓存环大小时,会根据失败率选择转换状态为CLOSED、OPEN -
熔断器从打开到半开的转换默认还需要请求进行触发,也可通过automaticTransitionFromOpenToHalfOpenEnabled=true设置为自动触发
-
服务降级成功后,会将本次调用计入成功率
-
recordExceptions异常失败列表,注意指定失败异常列表那么只有符合该异常列表的异常才被计入失败,其他异常都算成功,除非被ignoreException忽略
-
ignoreException忽略异常列表,出现该列表异常,那本次调用不会计入失败率(与文档不服还需测试)
-
滑动窗口含义为记录最新的
slidingWindowSize次调用,并在此窗口内计算失败率
Ratelimiter
简介
速率限制是一项必不可少的技术,可让您的 API 为规模做好准备并建立服务的高可用性和可靠性。而且,该技术还提供了大量不同的选项,用于处理检测到的剩余限制,或者您想要限制的请求类型。您可以简单地拒绝此超限请求,或者构建一个队列以稍后执行它们,或者以某种方式将这两种方法结合起来。
一般限速器在provider供应者服务内实现,方便预估限速调用次数,客户端实现无法预估集体调用数量
可配置参数
| 配置参数 | 默认值 | 描述 |
|---|---|---|
| timeoutDuration | 5[s] | 线程等待权限的默认等待时间 |
| limitRefreshPeriod | 500[ns] | 权限刷新的时间,每个周期结束后,RateLimiter将会把权限计数设置为limitForPeriod的值 |
| limitForPeriod | 50 | 一个限制刷新期间的可用权限数 |
pom依赖
1 | <!-- https://mvnrepository.com/artifact/io.github.resilience4j/resilience4j-circuitbreaker --> |
java配置Ratelimiter
1 |
|
RateLimiter工具类
1 | public class RateLimiterUtil { |
AOP式调用RateLimiter
API
1 |
|
pom.yml配置文件
1 | server: |
总结
- 超出周期权限的请求会被放在队列中等待下一次周期,但如果请求过期,那么将不会在下一周期中调用过期请求
- 限速器在provider供应商实现,方便预估调用次数
Retry
简介
同熔断器一样,重试组件也提供了注册器,可以通过注册器获取实例来进行重试,同样可以跟熔断器配合使用。
创建和配置Retry
您可以提供自定义的全局 RetryConfig。为了创建自定义全局 RetryConfig,您可以使用 RetryConfig 构建器。您可以使用构建器进行配置:
- 最大尝试次数
- 连续尝试之间的等待时间
- 自定义 IntervalBiFunction,它根据尝试次数和结果或异常计算失败后的等待间隔。
- 一个自定义谓词,用于评估某个响应是否应该触发重试尝试
- 一个自定义谓词,用于评估异常是否应触发重试尝试
- 应触发重试尝试的异常列表
- 应该被忽略并且不会触发重试尝试的异常列表
| 配置属性 | 默认值 | 描述 |
|---|---|---|
| maxAttempts | 3 | 最大尝试次数(包括首次调用作为第一次尝试) |
| waitDuration | 500 [毫秒] | 重试尝试之间的固定等待时间 |
| intervalFunction | numOfAttempts -> waitDuration | 用来改变重试时间间隔,可以选择指数退避或者随机时间间隔 |
| intervalBiFunction | (numOfAttempts, Each<throwable, result>) -> waitDuration | 根据尝试次数和结果或异常修改失败后等待间隔的函数。与 intervalFunction 一起使用时会抛出 IllegalStateException。 |
| retryOnResultPredicate | result -> false | 配置一个 Predicate 来评估是否应该重试结果。如果应重试结果,则谓词必须返回true,否则必须返回false。 |
| retryExceptionPredicate | throwable -> true | 配置一个 Predicate 来评估是否应该重试异常。如果应重试异常,则谓词必须返回true,否则必须返回false。 |
| retryExceptions | empty | 需要重试的异常列表 |
| ignoreExceptions | empty | 需要忽略的异常列表 |
| failAfterMaxRetries | false | 当重试达到配置的 maxAttempts 并且结果仍未通过 retryOnResultPredicate 时启用或禁用抛出 MaxRetriesExceededException 的布尔值 |
pom依赖
1 | <dependency> |
Java配置Retry
1 |
|
Retry工具类
1 |
|
控制台

可以看到只要没有超过最大重试次数时调用成功,那么整个方法就是成功的
AOP式调用ReTry
实际测试代码
ReTry控制器
1 | /** |
ReTry工具类
1 |
|
application.yml配置信息
1 | server: |
总结
- 当断路器注解
@CircuitBreaker和重试器@Retry一起使用时,每一次重试请求都会被断路器记录, - 服务降级只会在重试失败后调用
- 调用服务降级后,会被断路器计入成功率
Resilience4j配置文件
注意当如果Retry、CircuitBreaker、RateLimiter同时注解在方法上,默认的顺序是Retry>CircuitBreaker>RateLimiter,即先控制并发再限流然后熔断最后重试
1 | server: |
十,服务监控
在微服务中,由于服务数量众多,那么服务出现故障的几率也会非常大,那么维护这些服务就成了至关重要的事情了,服务监控也就成了必然的事情了
服务监控部分不再赘述
这里直接看健康信息可视化工具
Prometheus
官网文档:https://prometheus.io/docs/introduction/first_steps/
简单安装
下载Linux版的Prometheus后
解压
tar -zxvf prometheus-X.X.X.tar
进入工作目录
cd prometheus-2.30.1.linux-amd64/
修改prometheus.yml配置文件
注意,返回服务信息的URL所返回的数据必须是Protobuf格式
文档地址: https://prometheus.io/docs/instrumenting/exposition_formats/
1 | # my global config |
启动Prometheus
./prometheus --config.file=prometheus.yml
监控服务配置
引入prometheus依赖
1 | <!-- https://mvnrepository.com/artifact/io.micrometer/micrometer-registry-prometheus --> |
简单配置依赖
1 | management: |
Security配置
如果你的项目配置了SpringSecurity,请开放接口/actuator/prometheus的权限
访问地址
prometheusIP:9090
Grafana
官网地址: https://grafana.com/grafana/download?pg=get&plcmt=selfmanaged-box1-cta1&platform=docker
文档地址: https://grafana.com/docs/grafana/latest/basics/
Docker安装
基于ubuntu镜像
docker run -d --name=grafana -p 3000:3000 grafana/grafana-enterprise:8.1.5-ubuntu
添加Prometheus数据源

添加仪表盘
点击红框设置仪表盘展示信息

在输入框填写PrometheusSql语句即可将服务信息以图形化方式展示出来

十一,服务网关
Zuul已经闭源,这里不做描述
网关简介
一、什么是服务网关
1 | 服务网关 = 路由转发 + 过滤器 |
1、路由转发:接收一切外界请求,转发到后端的微服务上去;
2、过滤器:在服务网关中可以完成一系列的横切功能,例如权限校验、限流以及监控等,这些都可以通过过滤器完成(其实路由转发也是通过过滤器实现的)。
二、为什么需要服务网关
上述所说的横切功能(以权限校验为例)可以写在三个位置:
- 每个服务自己实现一遍
- 写到一个公共的服务中,然后其他所有服务都依赖这个服务
- 写到服务网关的前置过滤器中,所有请求过来进行权限校验
第一种,缺点太明显,基本不用;第二种,相较于第一点好很多,代码开发不会冗余,但是有两个缺点:
- 由于每个服务引入了这个公共服务,那么相当于在每个服务中都引入了相同的权限校验的代码,使得每个服务的jar包大小无故增加了一些,尤其是对于使用docker镜像进行部署的场景,jar越小越好;
- 由于每个服务都引入了这个公共服务,那么我们后续升级这个服务可能就比较困难,而且公共服务的功能越多,升级就越难,而且假设我们改变了公共服务中的权限校验的方式,想让所有的服务都去使用新的权限校验方式,我们就需要将之前所有的服务都重新引包,编译部署。
而服务网关恰好可以解决这样的问题:
- 将权限校验的逻辑写在网关的过滤器中,后端服务不需要关注权限校验的代码,所以服务的jar包中也不会引入权限校验的逻辑,不会增加jar包大小;
- 如果想修改权限校验的逻辑,只需要修改网关中的权限校验过滤器即可,而不需要升级所有已存在的微服务。
所以,需要服务网关!!!
三、服务网关技术选型

引入服务网关后的微服务架构如上,总体包含三部分:服务网关、open-service和service。
1、总体流程
- 服务网关、open-service和service启动时注册到注册中心上去;
- 用户请求时直接请求网关,网关做智能路由转发(包括服务发现,负载均衡)到open-service,这其中包含权限校验、监控、限流等操作
- open-service聚合内部service响应,返回给网关,网关再返回给用户
2、引入网关的注意点
- 增加了网关,多了一层转发(原本用户请求直接访问open-service即可),性能会下降一些(但是下降不大,通常,网关机器性能会很好,而且网关与open-service的访问通常是内网访问,速度很快);
- 网关的单点问题:在整个网络调用过程中,一定会有一个单点,可能是网关、nginx、dns服务器等。防止网关单点,可以在网关层前边再挂一台nginx,nginx的性能极高,基本不会挂,这样之后,网关服务就可以不断的添加机器。但是这样一个请求就转发了两次,所以最好的方式是网关单点服务部署在一台牛逼的机器上(通过压测来估算机器的配置),而且nginx与zuul的性能比较,根据国外的一个哥们儿做的实验来看,其实相差不大,zuul是netflix开源的一个用来做网关的开源框架;
- 网关要尽量轻。
3、服务网关基本功能
-
智能路由:接收外部一切请求,并转发到后端的对外服务open-service上去;
-
- 注意:我们只转发外部请求,服务之间的请求不走网关,这就表示全链路追踪、内部服务API监控、内部服务之间调用的容错、智能路由不能在网关完成;当然,也可以将所有的服务调用都走网关,那么几乎所有的功能都可以集成到网关中,但是这样的话,网关的压力会很大,不堪重负。
-
权限校验:只校验用户向open-service服务的请求,不校验服务内部的请求。服务内部的请求有必要校验吗?
-
API监控:只监控经过网关的请求,以及网关本身的一些性能指标(例如,gc等);
-
限流:与监控配合,进行限流操作;
-
API日志统一收集:类似于一个aspect切面,记录接口的进入和出去时的相关日志
-
。。。后续补充
上述功能是网关的基本功能,网关还可以实现以下功能:
- A|B测试:A|B测试时一块比较大的东西,包含后台实验配置、数据埋点(看转化率)以及分流引擎,在服务网关中,可以实现分流引擎,但是实际上分流引擎会调用内部服务,所以如果是按照上图的架构,分流引擎最好做在open-service中,不要做在服务网关中。
- 。。。后续补充
Gateway
文档地址:https://docs.spring.io/spring-cloud-gateway/docs/current/reference/html/
简介
Spring Cloud Gateway是Spring官方基于Spring 5.0,Spring Boot 2.0和Project Reactor等技术开发的网关,Spring Cloud Gateway旨在为微服务架构提供一种简单而有效的统一的API路由管理方式。Spring Cloud Gateway作为Spring Cloud生态系中的网关,目标是替代ZUUL,其不仅提供统一的路由方式,并且基于Filter链的方式提供了网关基本的功能,例如:安全,监控/埋点,和限流等。
优点
Spring Cloud Gateway 可以看做是一个 Zuul 1.x 的升级版和代替品,比 Zuul 2 更早的使用 Netty 实现异步 IO,从而实现了一个简单、比 Zuul 1.x 更高效的、与 Spring Cloud 紧密配合的 API 网关。
Spring Cloud Gateway 里明确的区分了 Router 和 Filter,并且一个很大的特点是内置了非常多的开箱即用功能,并且都可以通过 SpringBoot 配置或者手工编码链式调用来使用。
比如内置了 10 种 Router,使得我们可以直接配置一下就可以随心所欲的根据 Header、或者 Path、或者 Host、或者 Query 来做路由。
比如区分了一般的 Filter 和全局 Filter,内置了 20 种 Filter 和 9 种全局 Filter,也都可以直接用。当然自定义 Filter 也非常方便。
最重要的几个概念


RouteProperties匹配
时间匹配
Predicate 支持设置一个时间,在请求进行转发的时候,可以通过判断在这个时间之前或者之后进行转发。比如我们现在设置只有在 2021年 9 月 20 日才会转发到我的网站,在这之前不进行转发,我就可以这样配置:
1 | spring: |
Spring 是通过 ZonedDateTime 来对时间进行的对比,ZonedDateTime 是 Java 8 中日期时间功能里,用于表示带时区的日期与时间信息的类,ZonedDateTime 支持通过时区来设置时间,中国的时区是:Asia/Shanghai。
After Route Predicate 是指在这个时间之后的请求都转发到目标地址。上面的示例是指,请求时间在 2021年 9 月 20 日 6 点 6 分 6 秒之后的所有请求都转发到地址http://ityouknow.com。+08:00是指时间和 UTC 时间相差八个小时,时间地区为Asia/Shanghai。
添加完路由规则之后,访问地址http://localhost:8080会自动转发到http://httpbin.org。注意这里的转发只能转发到指定某个服务或者URL上,而不能转发到服务上某个具体的请求,比如:http://httpbin.org/get是不可行的。
Before Route Predicate 刚好相反,在某个时间之前的请求的请求都进行转发。我们把上面路由规则中的 After 改为 Before,如下:
1 | spring: |
就表示在这个时间之前可以进行路由,在这时间之后停止路由,修改完之后重启项目再次访问地址http://localhost:8080,页面会报 404 没有找到地址。
除过在时间之前或者之后外,Gateway 还支持限制路由请求在某一个时间段范围内,可以使用 Between Route Predicate 来实现。
1 | spring: |
这样设置就意味着在这个时间段内可以匹配到此路由,超过这个时间段范围则不会进行匹配。通过时间匹配路由的功能很酷,可以用在限时抢购的一些场景中。
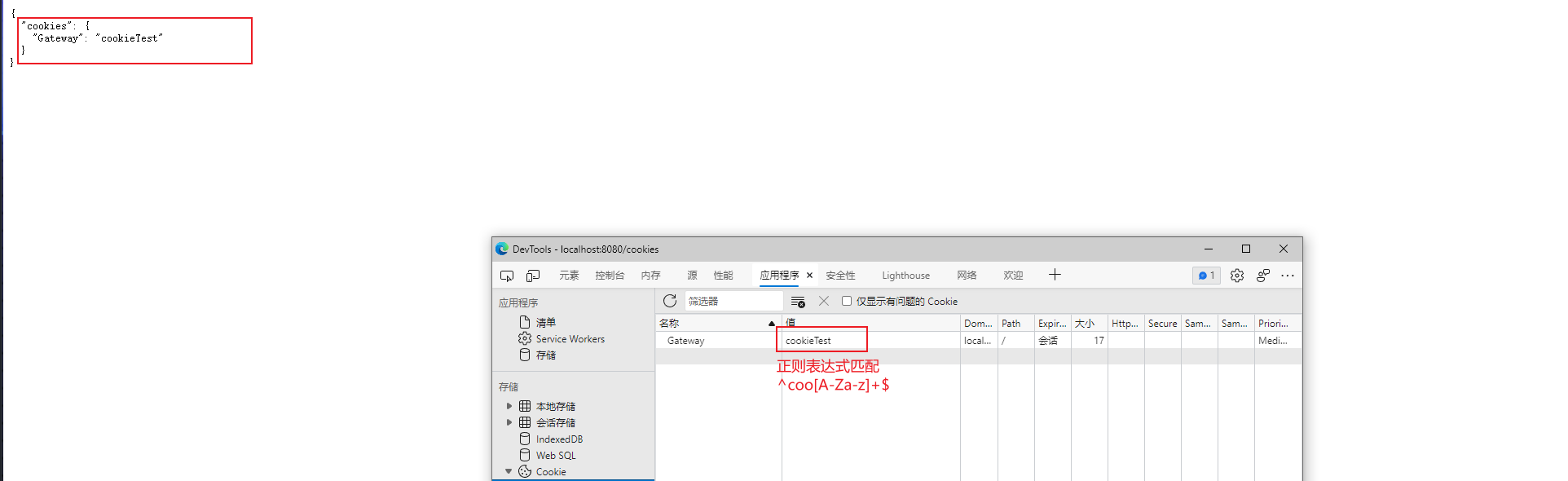
Cookie匹配
Cookie Route Predicate 可以接收两个参数,一个是 Cookie name , 一个是正则表达式,路由规则会通过获取对应的 Cookie name 值和正则表达式去匹配,如果匹配上就会执行路由,如果没有匹配上则不执行。
1 | spring: |
以上符合配置的Cookie为
name: Gateway
value: coo开头的值
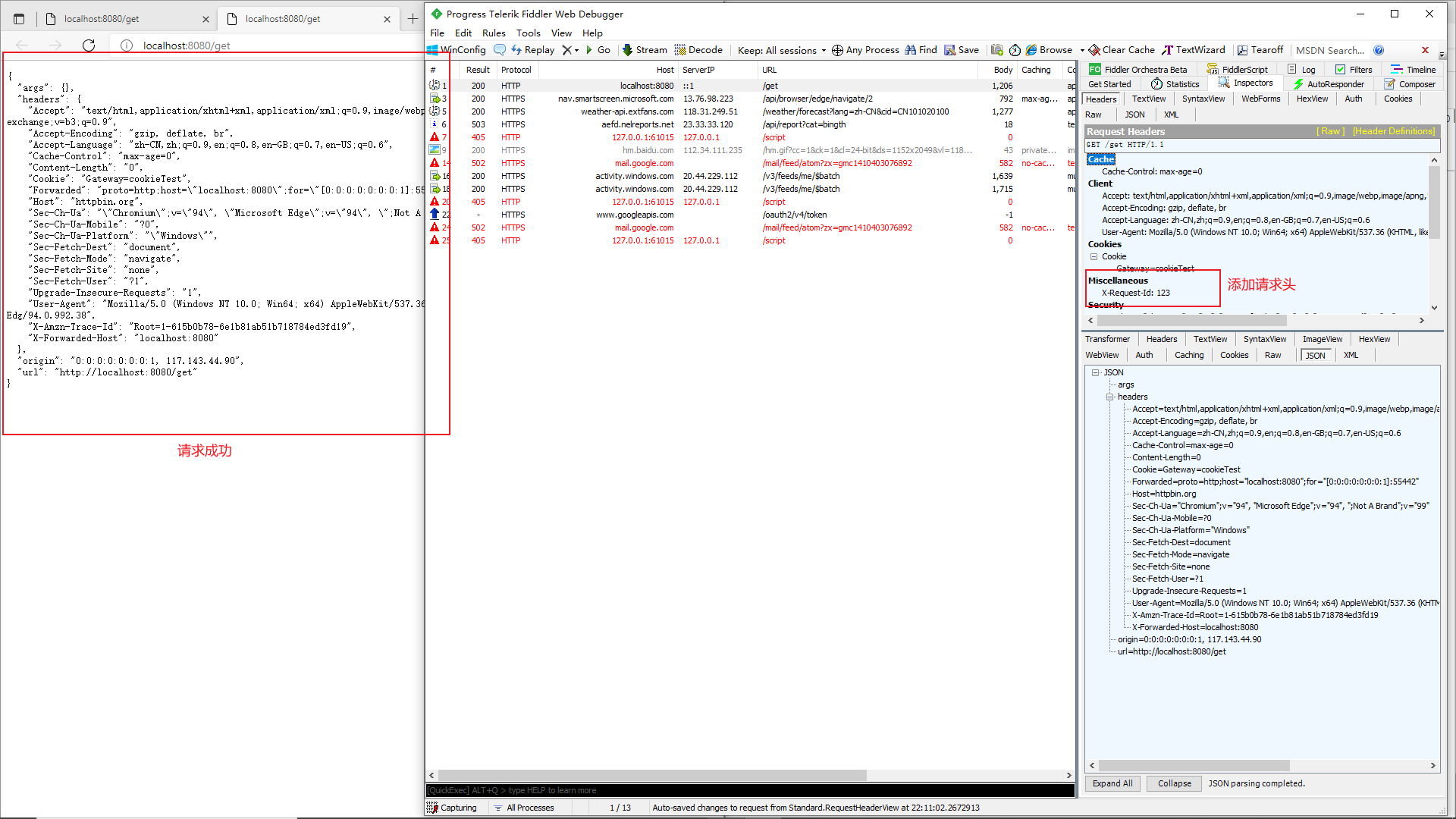
Header Route Predicate 和 Cookie Route Predicate 一样,也是接收 2 个参数,一个 header 中属性名称和一个正则表达式,这个属性值和正则表达式匹配则执行。
1 | spring: |
我们在Fiddler中拦截localhost:8080/get的请求,为其添加请求头,就可以发现请求成功
X-Request-Id:123
Host匹配
Host Route Predicate 接收一组参数,一组匹配的域名列表,这个模板是一个 ant 分隔的模板,用.号作为分隔符。它通过参数中的主机地址作为匹配规则。
1 | spring: |
使用 curl 测试,命令行输入:
curl http://localhost:8080 -H “Host: www.ityouknow.org”
curl http://localhost:8080 -H “Host: md.ityouknow.org”
经测试以上两种 host 均可匹配到 host_route 路由,去掉 host 参数则会报 404 错误。
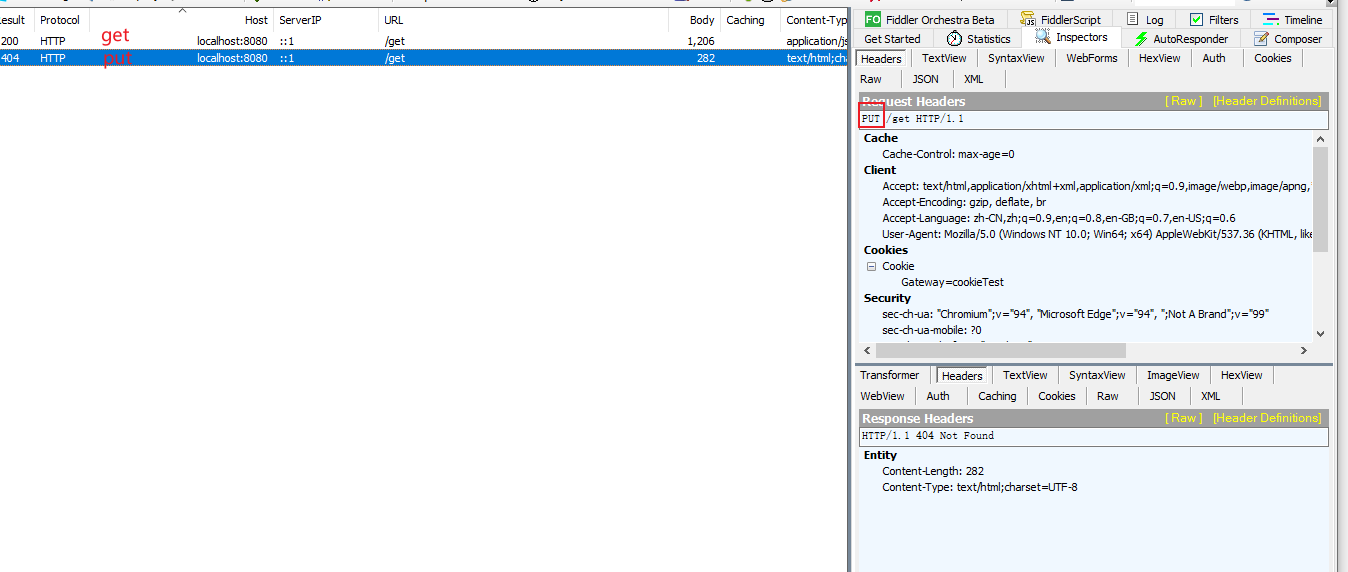
通过请求方式匹配
可以通过是 POST、GET、PUT、DELETE 等不同的请求方式来进行路由。
1 | spring: |
通过不同的请求方式可以看到,GET可以通过请求,而PUT请求直接404
通过请求路径匹配
Path Route Predicate 接收一个匹配路径的参数来判断是否走路由。
1 | spring: |
通过请求参数匹配
Query Route Predicate 支持传入两个参数,一个是属性名一个为属性值,属性值可以是正则表达式
1 | spring: |
以下URL可以匹配成功
通过请求 ip 地址进行匹配
Predicate 也支持通过设置某个 ip 区间号段的请求才会路由,RemoteAddr Route Predicate 接受 cidr 符号 (IPv4 或 IPv6) 字符串的列表(最小大小为 1),例如 192.168.0.1/16 (其中 192.168.0.1 是 IP 地址,16 是子网掩码)。
1 | spring: |
权重路由匹配
该Weight有两个参数:group和weight(一个int)。权重是按组计算的。
1 | spring: |
该路由会将约 80% 的流量转发到http://httpbin.org,将约 20% 的流量转发到https://example.org
结合Eureka注册中心
引入依赖
1 | <dependency> |
yaml配置文件
注意Gateway和注册中心整合时,务必开启注册中心客户端代理spring.cloud.gateway.discovery,enabled=true
1 | spring: |
检查Eureka注册中心上的服务

访问注册中心上的服务
url的前缀/PROVIDER-APPLICATION/必须为注册中心上某个服务的名称,同时注意大小写

Filter过滤器
Gateway的过滤器众多,这里不每个都看一遍,必要时查阅文档即可
-
AddRequestHeader在转发请求网关下游服务时,在请求头添加
AddRequestHeader所配置的参数 -
AddRequestParameter在转发请求网关下游服务时,在参数体中添加
AddRequestParameter所配置的参数 -
AddResponseHeader在返回调用者之前,在响应头中添加
AddResponseHeader配置的参数 -
CircuitBreaker结合Resilience4j的CircuitBreaker断路器
-
引入依赖,注意一定是反应式
reactor的CircuitBreaker的依赖1
2
3
4<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-circuitbreaker-reactor-resilience4j</artifactId>
</dependency> -
配置
CircuitBreaker1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44#Resilience4J配置
resilience4j:
#circuitbreaker配置
circuitbreaker:
#修改默认的配置
configs:
default:
#断路器失败阈值百分比
failureRateThreshold: 50
#超时请求阈值百分比
slowCallRateThreshold: 70
#超时时长阈值 3秒
slowCallDurationThreshold: 3000
#断路器half_open时允许调用的数量
permittedNumberOfCallsInHalfOpenState: 10
#滑动窗口缓冲区类型
#如果滑动窗口是COUNT_BASED,则记录并聚合最后的' slidingWindowSize '调用。
#如果滑动窗口是TIME_BASED,则记录并聚合最后一个' slidingWindowSize '秒的调用。
slidingWindowType: COUNT_BASED
#断路器关闭时记录通话结果的滑动窗口的大小
slidingWindowSize: 5
#在计算错误率或者计算慢速呼叫率最小呼叫数
minimumNumberOfCalls: 10
#断路器由open状态到half_open状态需要的时间 6秒
waitDurationInOpenState: 60000
#true 开启一个线程监听CircuitBreakers的所有实例,一旦waitDurationInOpenState通过,就将它们转换到HALF_OPEN。
#false 转换到HALF_OPEN只在调用时发生,即使在waitDurationInOpenState被传递之后。
automaticTransitionFromOpenToHalfOpenEnabled: false
#记录为失败的异常列表,从而增加失败率
#注意指定失败异常列表那么只有符合该异常列表的异常才被计入失败,其他异常都算成功,除非被ignoreException忽略
recordExceptions:
#忽略的异常列表,不计入失败
ignoreException:
#创建配置实例
instances:
#实例A 覆盖一些默认配置
breakerA:
baseConfig: default
minimumNumberOfCalls: 2
waitDurationInOpenState: 2000
permittedNumberOfCallsInHalfOpenState: 2
breakerB:
baseConfig: default -
在router匹配中加入
CircuitBreaker过滤器1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17spring:
cloud:
gateway:
routes:
# 根据权重匹配
- id: weight_high
uri: http://httpbin.org
predicates:
- Weight=group1, 8
filters:
- AddRequestHeader=name,zhangsan
- AddResponseHeader=response-headers,test
- CircuitBreaker=breakerA
- id: weight_low
uri: https://example.org
predicates:
- Weight=group1, 2最后,我们的断路器就在该router匹配中生效了,但是注意的是一定是
circuitbreaker-reactor-resilience4j依赖而不是circuitbreaker-resilience4j
-
-
SaveSession将客户端的session信息,连同请求和session一起转发到下游服务上,确保安全详细信息能够发送到下游服务器
过滤器有很多,这里不一一赘述,如果有需求可以查阅SpringColud Gateway官方文档
Http超时配置
可以为所有路由配置 Http 超时(响应和连接),并为每个特定路由覆盖。
全局超时配置
1 | spring: |
特定路由覆盖
要配置每条路由超时:
connect-timeout必须以毫秒为单位指定。response-timeout必须以毫秒为单位指定。
1 | - id: per_route_timeouts |
十二,SpringCoudConfig
简介
Spring Cloud Config为分布式系统中的外部配置提供服务器和客户端支持。使用Config Server,您可以在所有环境中管理应用程序的外部属性。客户端和服务器上的概念映射与Spring Environment和PropertySource抽象相同,因此它们与Spring应用程序非常契合,但可以与任何以任何语言运行的应用程序一起使用。随着应用程序通过从开发人员到测试和生产的部署流程,您可以管理这些环境之间的配置,并确定应用程序具有迁移时需要运行的一切。服务器存储后端的默认实现使用git,因此它轻松支持标签版本的配置环境,以及可以访问用于管理内容的各种工具。可以轻松添加替代实现,并使用Spring配置将其插入。
ConfigServer
准备工作
首先,我们知道Spring Clod Config是结合Git使用的,所以我们需要创建一个可以存放Spring配置文件的仓库,
仓库的创建,以及配置文件的上传这里不赘述
我们直接来看创建好的仓库,内部包含四个配置文件,接下来我们使用Spring Clod Config Server服务来访问这些配置文件
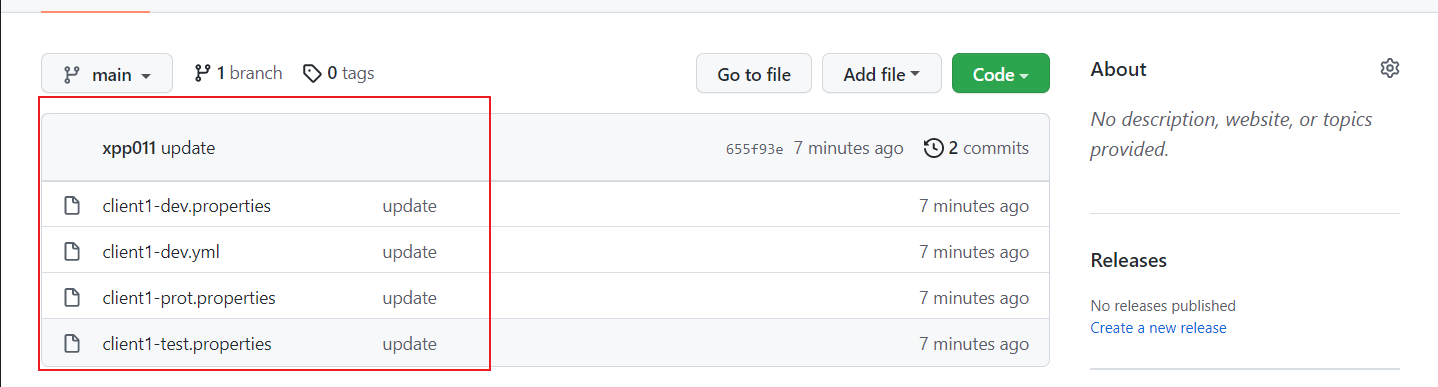
创建Spring Clod Config Server服务
引入依赖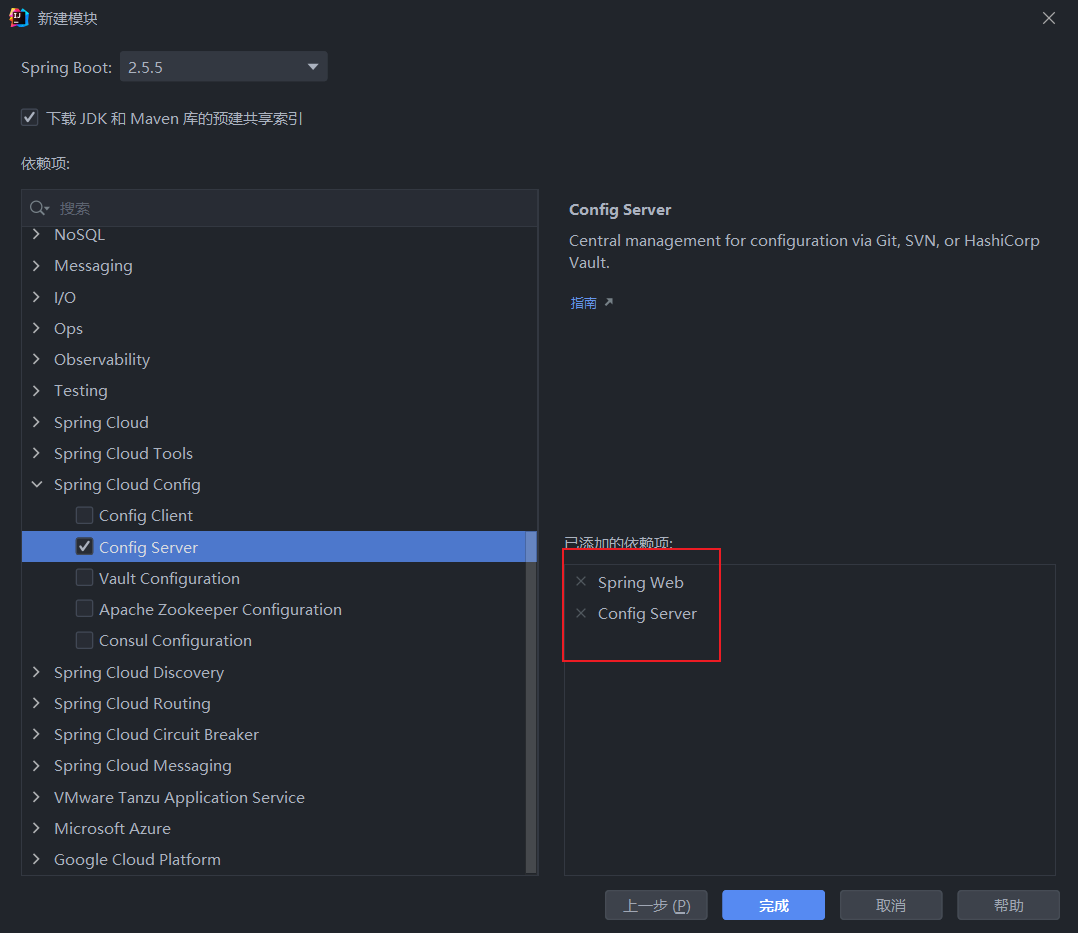
配置
创建Spring Clod Config Server服务后,需要在启动类上加入@EnableConfigServer注解,声明这是一台配置服务
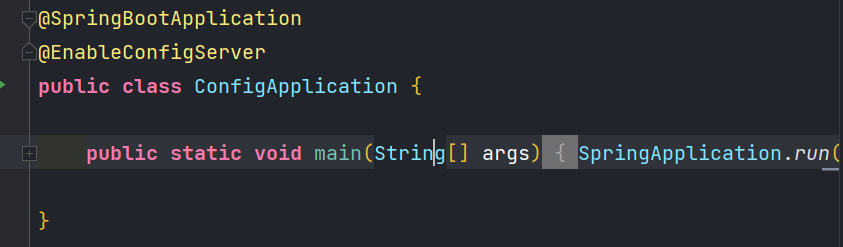
application配置
- {application}—>占位符,请求连接的client的
spring.application.name属性值
注意!!!
在yaml文件中单独使用占位符时必须使用``单引号括起来
1 | spring: |
最后我们就可以在浏览器中通过url访问配置文件了
以下几种方式的URL都可以访问到配置文件
- application—配置文件的应用名称
- profile—配置文件的环境
- label—git分支
1 | /{application}/{profile}[/{label}] |
ConfigClient
创建项目
引入依赖
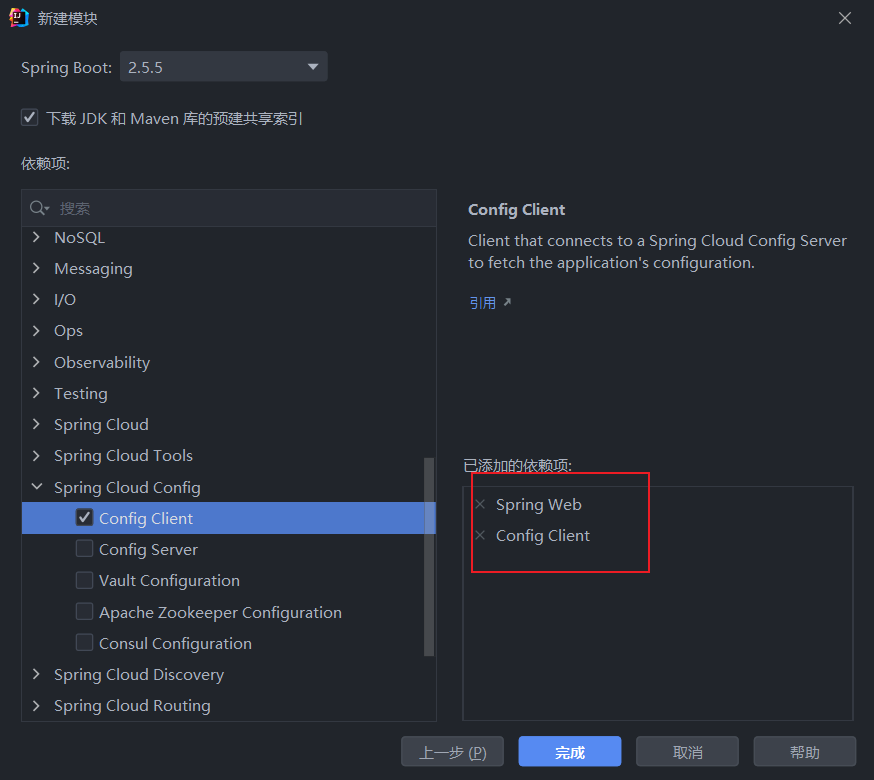
注意
注意在SpringBoot2.4之后使用bootstrap.yml | bootstrap.properties引导文件需要引入spring-cloud-starter-bootstrap依赖
1 | <dependency> |
如果不使用bootstrap.yml | bootstrap.properties引导文件,配置configServer则在application.yml中加入以下属性
spring.config.import=optional:configserver:http://myhost:8888
配置文件
bootstrap.yml配置
在bootstrap.yml中需要配置configserver服务信息
1 | spring: |
application.yml配置
为了验证配置文件是否生效
我们自定义了两个属性activate和serveractivate
1 | activate: "null" |
验证接口
我们在git仓库中的配置文件配置了不同的serveractivate属性
1 |
|
获取配置信息eureka
通过eureka获取配置信息的好处就是,ConfigServer服务可以随意改变坐标,而不用修改每一个ConfigSlient服务的配置文件
具体操作非常简单
引入依赖
首先我们需要将ConfigServer和ConfigClient注册到Eureka上去
1 | <dependency> |
配置ConfigServer
ConfigServer的配置非常简单,只需简单配置以下Eureka的服务地址即可
1 | spring: |
配置ConfigClient
ConfigClient的配置第一步也是注册到Eureka上
1 | eureka: |
然后我们需要开启配置文件的服务发现
spring.cloud.config.discovery.enabled=true(默认为false)
最后我们需要指定注册中心上ConfigServer的服务名称,也就是ConfigServer配置文件中属性spring.application.name的值的大写
我们也可以去eureka上去查看

配置属性
spring.cloud.config.discovery.serviceId=CONFIG-SERVER (默认服务 ID 是
configserver)
最后别忘了取消属性~~spring.cloud.config.uri~~我们已经不需要它了
bootstrap.yml文件完整配置
1 | spring: |
配置文件的加解密
在分布式环境下,一些由运维工程师掌握的敏感信息现在不得不写在配置文件中了,这样网传的程序员删库跑路的段子可能就成真了!但是在微服务中,我们又不太可能让运维工程师手动去维护这些信息,因为工作量太大了,那么一个好的办法,就是对这些配置信息进行加密,
常见加密方法
说到加密,需要先和大家来捋一捋一些常见的加密策略,首先,从整体上来说,加密分为两大类:
-
不可逆加密
不可逆加密就是大家熟知的在 Spring Security 或者 Shiro 这一类安全管理框架中我们对密码加密经常采取的方案。这种加密算法的特点就是不可逆,即理论上无法使用加密后的密文推算出明文,常见的算法如 MD5 消息摘要算法以及 SHA 安全散列算法, SHA 又分为不同版本,这种不可逆加密相信大家在密码加密中经常见到。
-
可逆加密
可逆算法看名字就知道,这种算法是可以根据密文推断出明文的,可逆算法又分为两大类:
- 对称加密
对称加密是指加密的密钥和解密的密钥一致,例如 A 和 B 之间要通信,为了防止别人偷听,两个人提前约定好一个密钥。每次发消息时, A 使用这个密钥对要发送的消息进行加密,B 收到消息后则使用相同的密钥对消息进行解密。这是对称加密,常见的算法有 DES、3DES、AES 等。
- 非对称加密
对称加密在一些场景下并不适用,特别是在一些一对多的通信场景下,于是又有了非对称加密,非对称加密就是加密的密钥和解密的密钥不是同一个,加密的密钥叫做公钥,这个可以公开告诉任何人,解密的密钥叫做私钥,只有自己知道。非对称加密不仅可以用来做加密,也可以用来做签名,使用场景还是非常多的,常见的加密算法是 RSA 。
配置文件加密肯定是可逆加密,不然给我一个加密后的字符串,我拿着也没用,还是没法使用。可逆算法中的对称加密和非对称加密在 Spring Cloud Config 中都得到支持,下面我们就分别来看。
对称加密
Java 中提供了一套用于实现加密、密钥生成等功能的包 JCE(Java Cryptography Extension),这些包提供了对称、非对称、块和流密码的加密支持,但是默认的 JCE 是一个有限长度的 JCE ,我们需要到 Oracle 官网去下载一个不限长度的 JCE :
不限长度JCE下载地址
下载完成后,将下载文件解压,解压后的文件包含如下三个文件:

将local_policy.jar和US_export_policy.jar两个文件拷贝到 JDK 的安装目录下,具体位置是 %JAVA_HOME%\jre\lib\security ,如果该目录下有同名文件,则直接覆盖即可。
然后我们在ConfigServer服务中配置对称加密的密钥
注意该配置需要加在bootstrap.yml引导文件中
此外我们还需要开启健康监控,方便查看暴露端点
所以我们需要引入以下依赖
1 | <dependency> |
bootstrap.yml配置
1 | #对称加密的密钥 |
配置完成后启动服务,我们查看端点
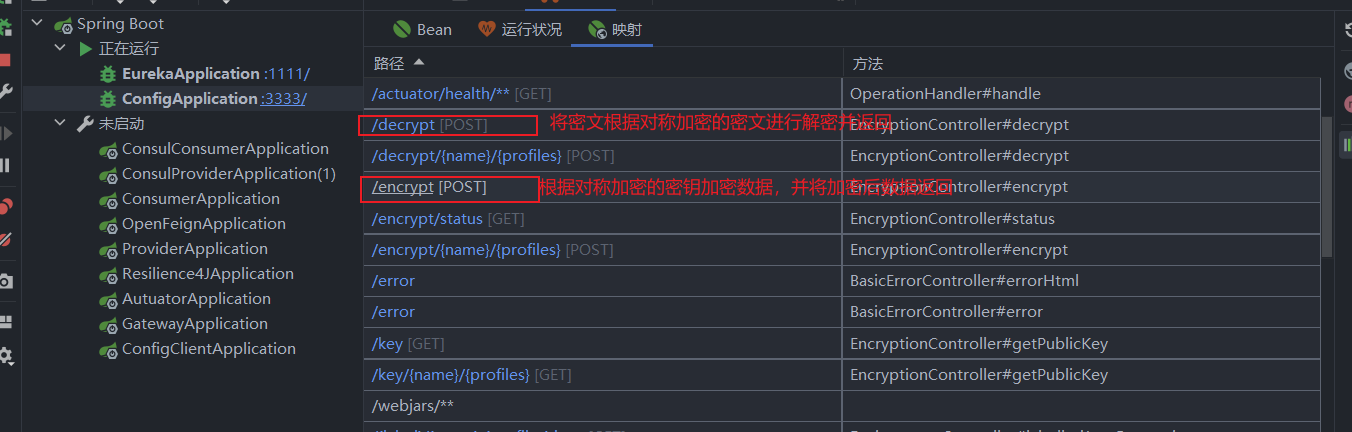
我们可以将需要加密的密码进行加密,得到密文后,写在目标配置文件中
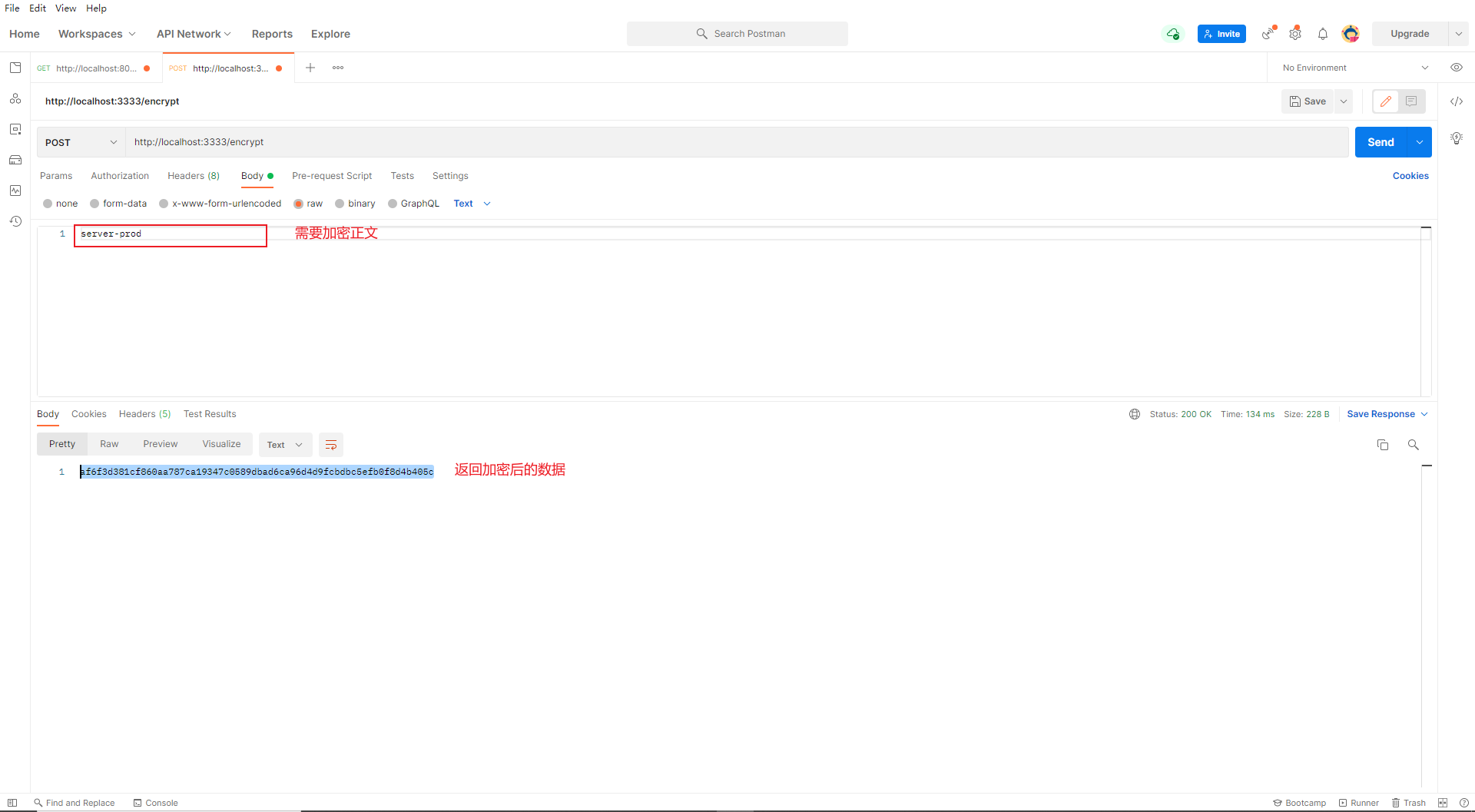
注意
- 为了区分密文和正常的字符串,我们需要在密文前机加上
{cipher}前缀,标识它是一串密文 - 在
yaml配置文件中,具有特殊含义的字符一定要加上‘单引号

我们可以在ConfigServer服务上查看该配置文件

非对称加密
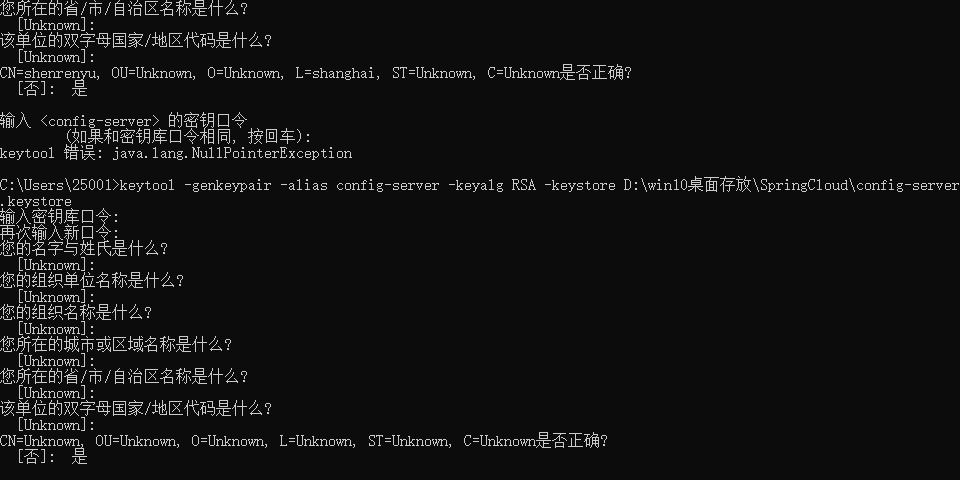
当然我们也可以使用非对称加密的方式来对配置文件进行加密,非对称加密要求我们先有一个密钥,密钥的生成我们可以使用 JDK 中自带的 keytool。keytool 是一个 Java 自带的数字证书管理工具 ,keytool 将密钥(key)和证书 (certificates) 存在一个称为 keystore 的文件中。具体操作步骤如下:
首先打开命令行窗口,输入如下命令:
keytool -genkeypair -alias config-server -keyalg RSA -keystore D:\win10桌面存放\SpringCloud\config-server.keystore
上面参数的解释如下:
-
-genkeypair 表示生成密钥对
-
-alias 表示 keystore 关联的别名
-
-keyalg 表示指定密钥生成的算法
-
-keystore 指定密钥库的位置和名称
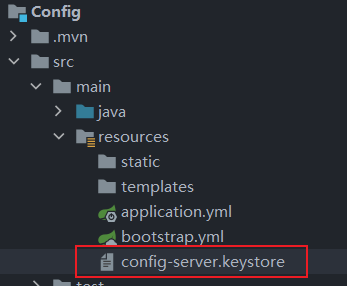
执行过程中,密钥库口令需要牢记,这个我们在后面还会用到。其它的信息可以输入也可以直接回车表示 Unknown ,自己做练习无所谓,实际开发中还是建议如实填写。
好了,这个命令执行完成后,在 D:\win10桌面存放\SpringCloud路径下就会生成一个名为 config-server.keystore 的文件,将这个文件直接拷贝到 ConfigServer服务项目的 classpath 下,如下:
然后我们需要在bootstrap.yml配置文件中简单配置
1 | #对称加密的密钥 |
注意:
如果无法加载证书,请检查maven生成target文件时是否把证书过滤掉了
服务启动完成后,访问接口/encrypt加密正文
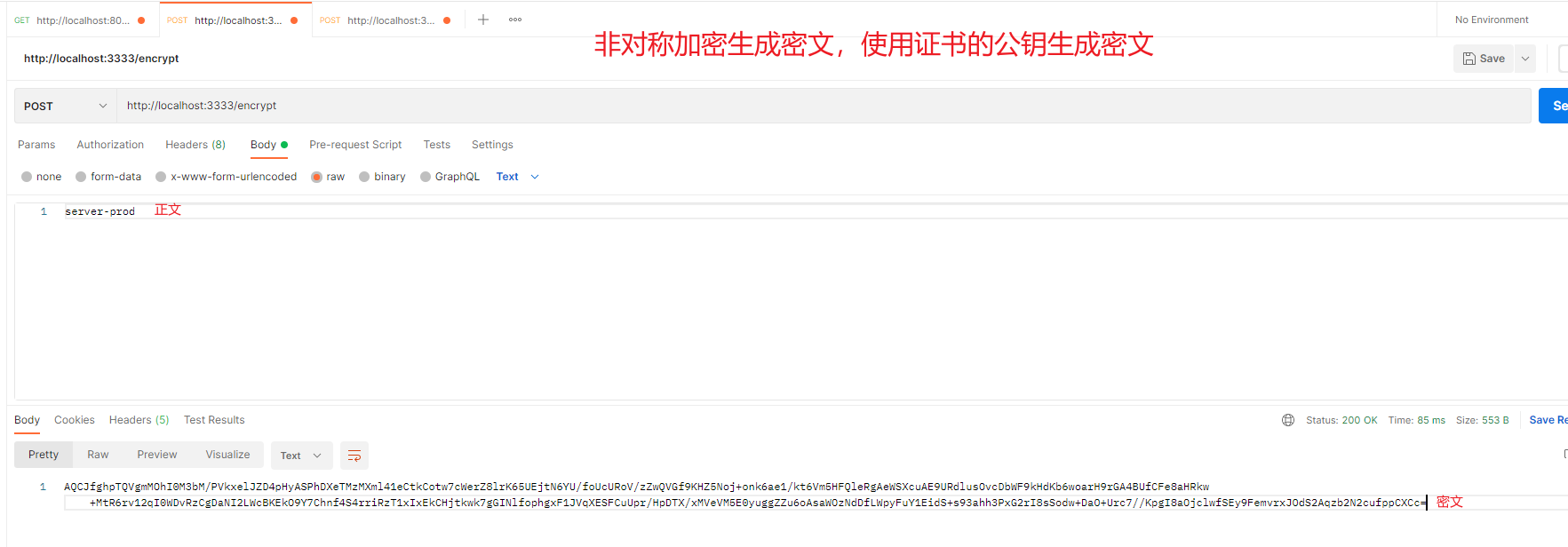
也可访问接口/decrypt,将密文解密
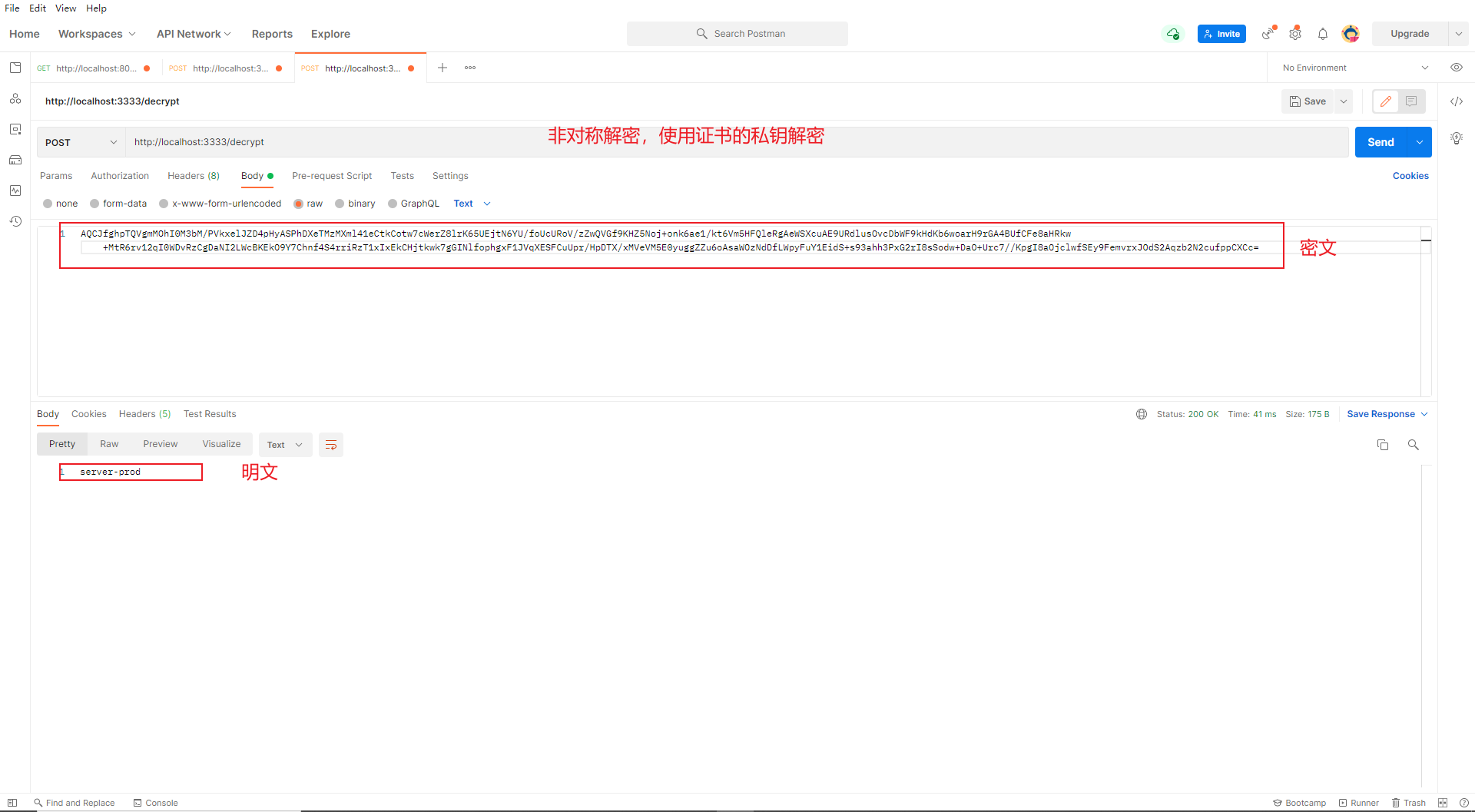
同理,我们将密文写在git仓库的配置文件之中

由此可以看出,所有的加密解密工作全部交给ConfigServer服务,而ConfigClient只负责获取配置
安全管理
目前的 ConfigServer 存在很大的安全隐患,因为所有的数据都可以不经过 ConfigClient 直接访问。出于数据安全考虑,我们要给 ConfigServer 中的接口加密。在 Spring Boot 项目中,项目加密方案当然首选 Spring Security ,使用Spring Security也很简单,只需要在 ConfigServer 项目中添加如下依赖即可:
1 | <dependency> |
在ConfigServer的配置文件中简单配置一下Security
1 | security: |
注意此时,我们再去访问ConfigServer服务的接口就需要登录了,证明ConfigServer服务起到了保护作用
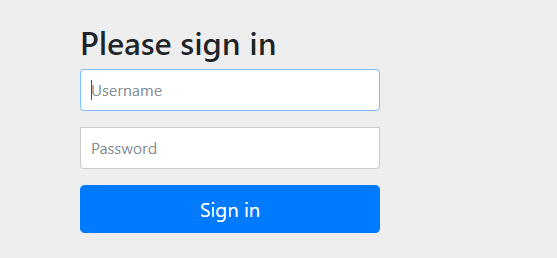
如果此时我们的ConfigClient不去配置登录信息的话就无法在ConfigServer拿取配置文件了
配置ConfigClient的bootstrap.yml文件
1 | spring: |
动态刷新
在更改Git仓库的配置文件后,服务的配置发生了变化,此时服务不能及时的重启去加载新的配置文件,为了解决整个问题,我们需要让服务可以实现配置文件的动态刷新
Autuator实现
该方法只是简单的实现了动态刷新,引用Autuator依赖只是为了使用其中的/actuator/refresh端点重启服务
在ConfigClient引入依赖
1 | <dependency> |
暴露/refresh端点
1 | management: |
更改配置文件后调用端点/actuator/refresh对应用进行重启,重加载配置文件
客户端重试
由于在分布式体系中,分区容错、网络波动的情况非常常见,在此期间注册中心,客户端服务,配置服务都有可能出现网络波动,那我的客户端请求不到配置就算了吗,肯定不是这样的,我们需要在网络波动的时候不断的请求我们的配置
快速失败
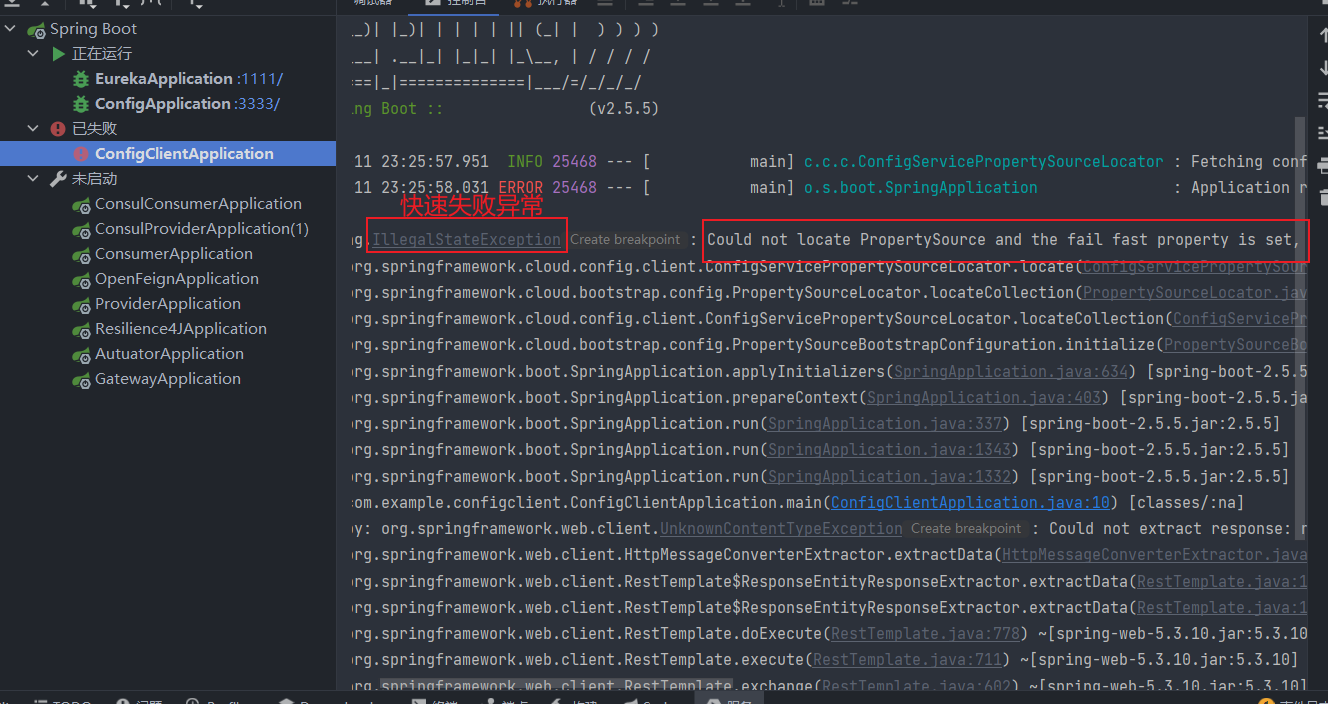
首先我们需要配置客户端无法来连接配置服务器时快速失败,而不是略过,加载下一配置
1 | =true |
这样在我们的服务请求不到配置时,就直接抛异常快速失败
请求重试
需要将spring-retry和添加spring-boot-starter-aop到我们的项目之中
1 | <dependency> |
默认行为是重试六次,初始退避间隔为 1000 毫秒,后续退避的指数乘数为 1.1。可以通过设置spring.cloud.config.retry.*配置属性来配置这些属性(和其他属性)
可以看到,配置客户端重试非常简单,只需引入依赖,即可马上开箱即由
以下是,客户端在请求不到配置时,不断尝试请求
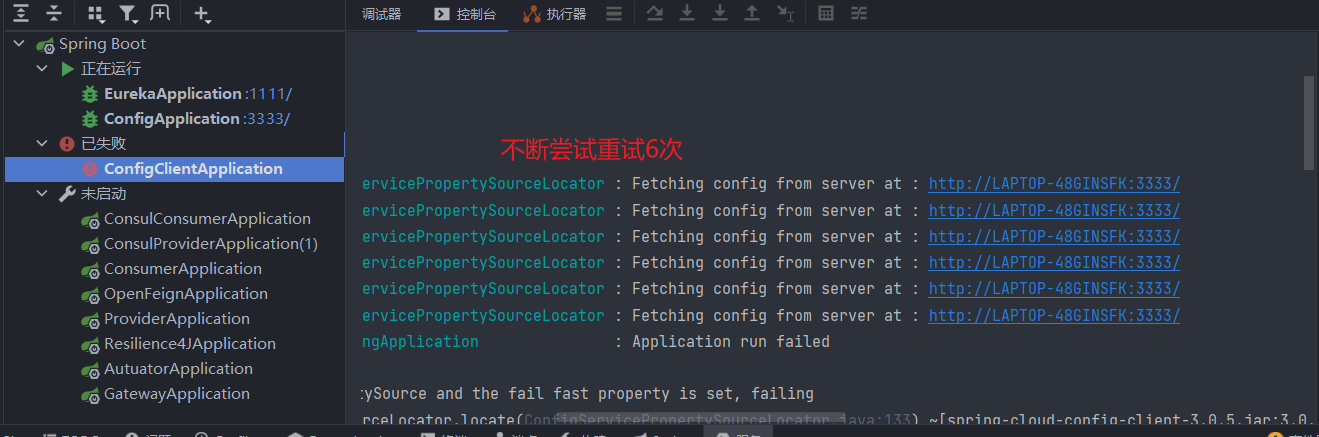
我们也可以配置spring.cloud.config.retry.*重试规则
1 | spring: |
配置详解
-
max-attempts最大重试次数
-
initial-interval重试间隔
-
max-interval最大重试间隔
-
multiplier后续退避的指数乘数
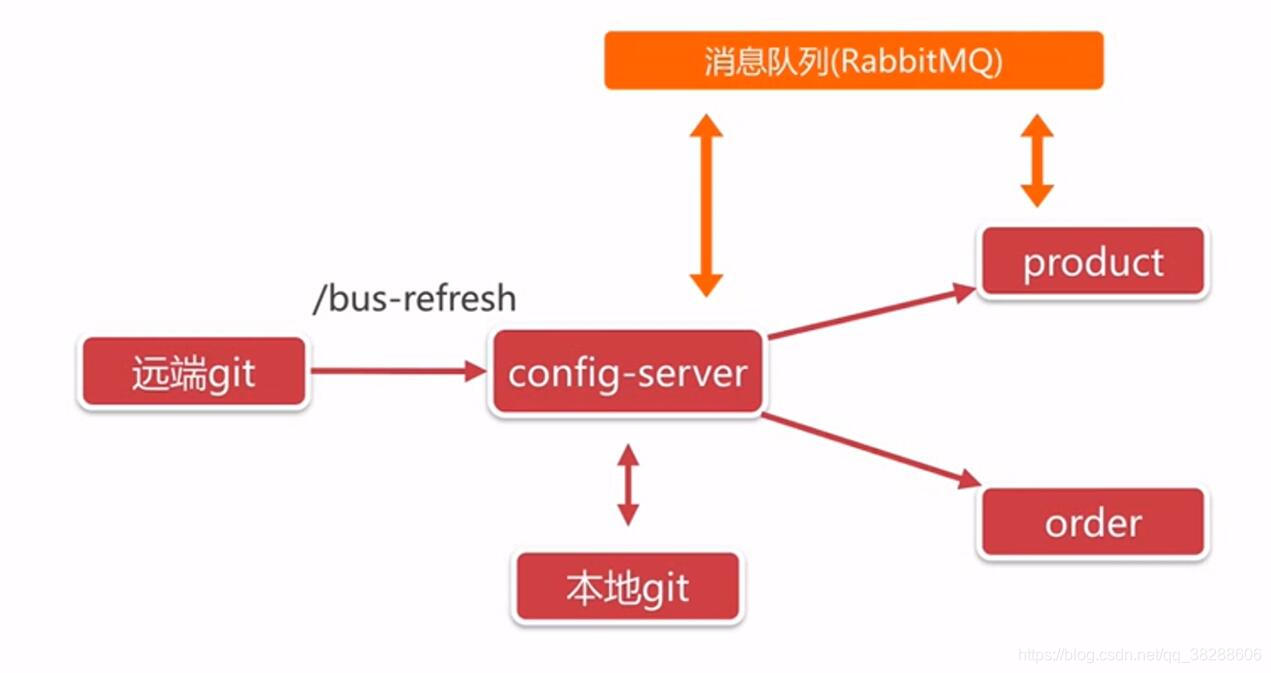
十三,SpringCloudBus
Spring Cloud Bus 将分布式系统的节点与轻量级消息代理连接起来。然后可以使用此代理来广播状态更改(例如配置更改)或其他管理指令。一个关键的想法是,总线就像一个用于横向扩展的 Spring Boot 应用程序的分布式执行器。但是,它也可以用作应用程序之间的通信渠道。该项目为 AMQP 代理或 Kafka 提供启动器作为传输。
快速入门
如果需要使用SpringCloudBus消息总线,那么需要引入依赖spring-cloud-starter-bus-amqp或 添加spring-cloud-starter-bus-kafka,SpringCloudBus启动器涵盖了 Rabbit 和 Kafka,因为这是两个最常见的实现。
但是,
Spring Cloud Stream非常灵活,并且与spring-cloud-bus很好的结合
1 | <dependency> |
配置rabbitMq以及actuator
1 | spring: |
总线端点
busrefresh
-
/actuator/busrefresh针对
ConfigServer的接口由于通知接入RabbitMq的服务进行刷新配置重启操作
注意
busrefresh接口确实可以将客户端服务进行重新加载配置操作
但是注意如果需要有一个接口查看配置信息,如果以下代码块,使用
$符号引用配置文件值,如果在配置未重新加载前获取该值,那么该值会一直保留重新加载前的值,即使服务重新加载配置后,该值还是保留原来jvm加载的值。如果希望,该值可以随着配置文件的加载而加载,需要在该类上加上
@RefreshScope注解即可
2
private String activate;
busrefresh/**
通过目标路径指定服务刷新配置
应用程序的每个实例都有一个服务 ID,它的值可以设置 spring.cloud.bus.id,默认值是从环境中构造的spring.application.name和 server.port(或spring.application.index,如果设置)的组合。ID的默认值以 的形式构造app:index:id,其中:
app是vcap.application.name,如果它存在,或者spring.application.nameindex是vcap.application.instance_index, 如果存在,spring.application.index,local.server.port,server.port, 或0(按此顺序)。id是vcap.application.instance_id,如果存在,或者是一个随机值。(不存在则不参与改造ID)
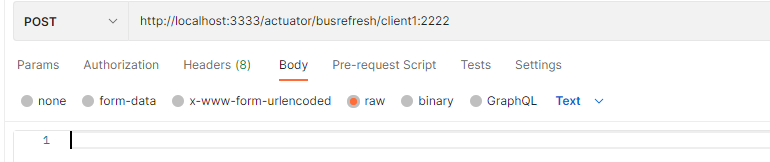
HTTP 端点接受“目标”路径参数,例如 busrefresh/client1:2222,其中destination是服务 ID。如果该 ID 由总线上的一个实例拥有,它会处理该消息,而所有其他实例将忽略它。
实例
我们启用两个客户端分别是2222和2223端口

更改Git仓库中的配置文件
然后通过Postman请求带有指定“目标”的路径
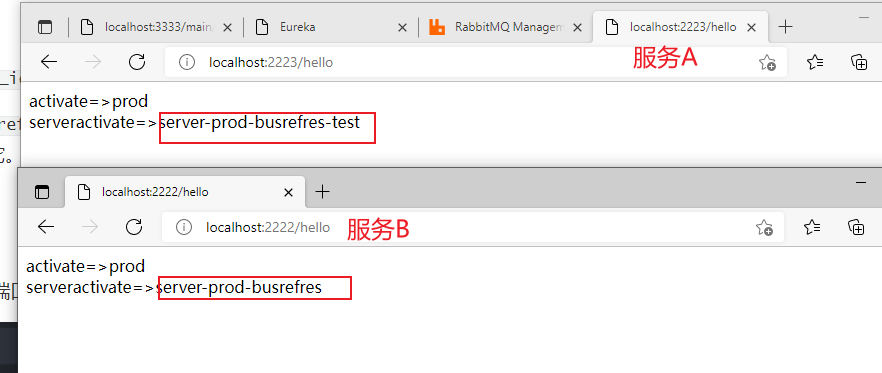
最后我们查看两个服务查看配置文件属性的接口,可以发现,成功指定了服务进行刷新配置
十四,SpringCloudStream
Spring Cloud Stream 是用于构建消息驱动的微服务应用程序的框架。Spring Cloud Stream 构建在 Spring Boot 的基础上,以创建独立的、生产级的 Spring 应用程序,并使用 Spring Integration 提供与消息代理的连接。它提供了来自多个供应商的中间件的自以为是的配置,介绍了持久发布订阅语义、消费者组和分区的概念。
通过简单地将 spring-cloud-stream 依赖项添加到应用程序的类路径,您将立即连接到通过提供的 spring-cloud-stream 绑定器公开的消息代理(稍后会详细介绍),并且您可以实现您的功能需求使用简单的基于传入消息执行
快速开始
创建具有以下依赖的服务

创建一个消费者
1 |
|
简单配置一下application.yml
1 | spring: |
此时我们在rabbitMq发送消息时,该bean就会接收到

自定义通道
我们可以通过SpringCloudStream3.0的bean方式来创建供应商消费者
1 |
|
- 输入 -
<functionName> + -in- + <index> - 输出 -
<functionName> + -out- + <index>
in和out对应于结合的类型(如输入或输出)
index是输入或输出的结合的索引。对于典型的单个输入/输出函数,它始终为 0,因此它仅与具有多个输入和输出参数的函数相关。
消费者
1 |
|
供应商
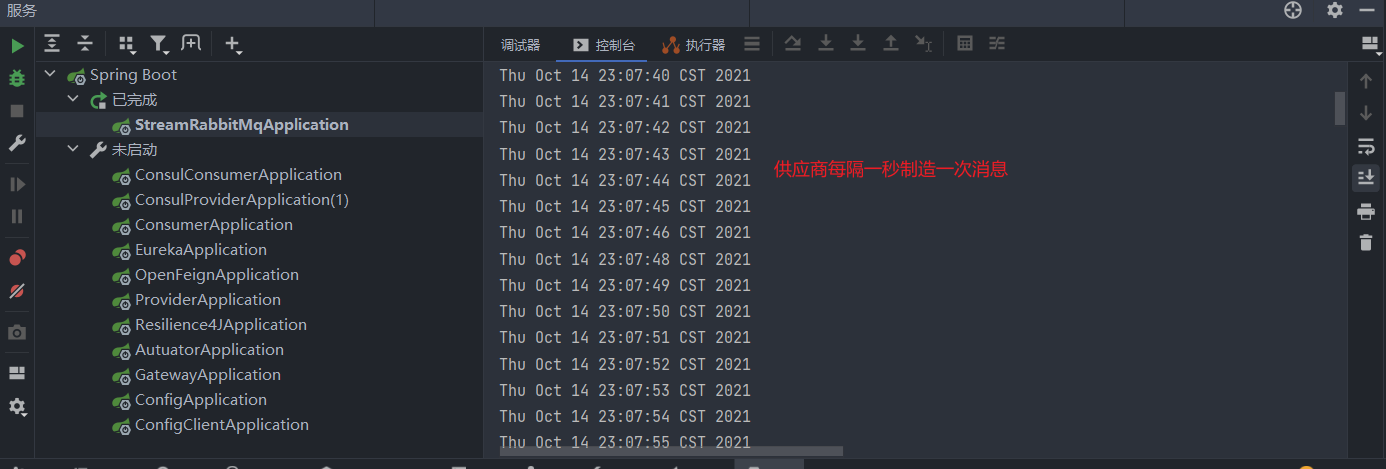
Supplier的默认触发调用方式是一秒执行一次,也就是说该供应商将会每一秒制造一次消息
如果我们不想让Supplier采用轮询的方式制造消息,我们直接让该方法返回null即可
@Bean
public SuppliernoPoll() { return () -> null;}
具体可查看触发方式
1 |
|
以上代码我们创建好了供应商,消费者
接下来我们需要将他们两个进行绑定,绑定的名称规则需要符合名称规则
application.yml
1 | spring: |
值得注意的是,当我们创建多个类型的java.util.function.[Supplier/Function/Consumer]Bean时,我们需要通过spring.cloud.function.definition进行声明,同时这也是必须的
效果
Function并且Consumer在涉及如何触发它们的调用时非常简单。它们是根据发送到它们绑定到的目的地的数据(事件)触发的。换句话说,它们是经典的事件驱动组件。
但是,Supplier在触发方面属于它自己的类别。由于根据定义,它是数据的源(源),它不订阅任何入站目的地,因此必须由一些其他机制触发。还有的问题Supplier实现方式中,这可能是必要的或反应性和其直接涉及这样的供应商的触发。
1 |
|
Supplier每当get()调用其方法时,前面的bean 都会生成一个字符串。但是,谁调用这个方法,多久调用一次?该框架提供了一个默认的轮询机制(回答“谁?”的问题),它将触发供应商的调用,并且默认情况下它会每秒执行一次(回答“多久?”的问题)。换句话说,上述配置每秒生成一条消息,并且每条消息都发送到output由绑定器公开的目的地。要了解如何自定义轮询机制,请参阅轮询配置属性部分。
分组
当我们在两个服务内同时订阅了输入通道now-in-0,同时绑定的路由也是同一个,那么这两个服务都会同时消费输入通道now-in-0内的消息,也就是说一个通道的消息被消费了两次,那如果我们想要实现一个通道的消息只被消费一次该怎么办呢,
这时就有了分组的概念
使用配置将输入通道分到g1组
1 | .... |
可以看到,rabbitMq创建了一个g1队列,该队列下有两个消费者,对应着服务A和服务B

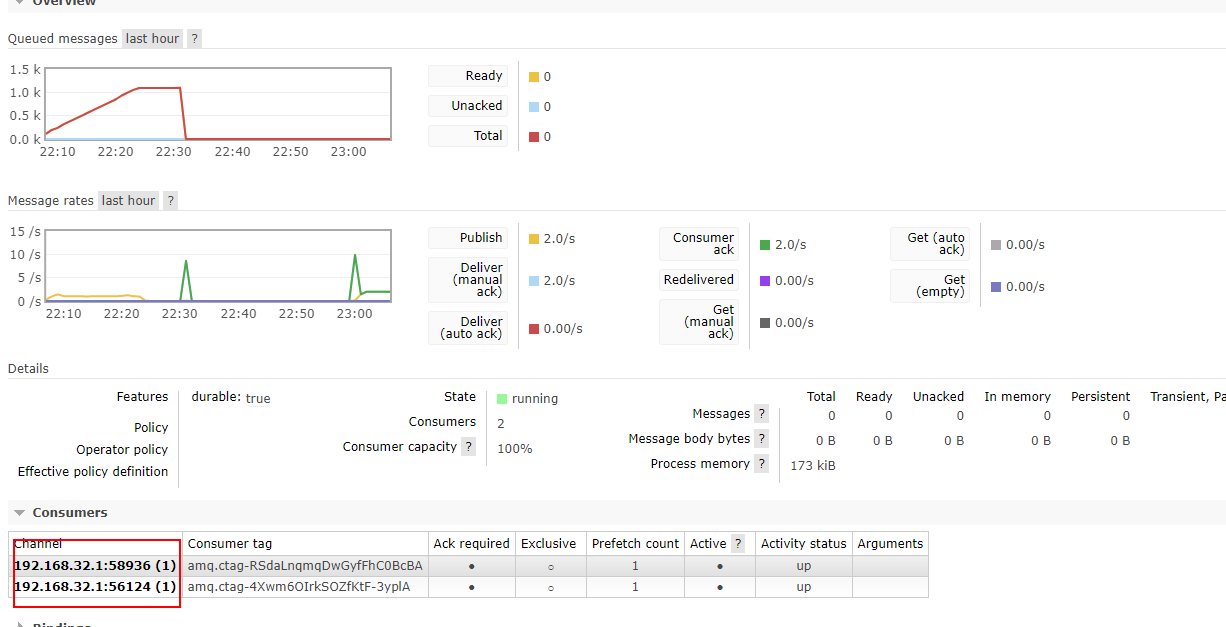
此时,这两个消费者,会采用轮询的方式消费该队列的消息,而不再是一个消息被消费两次或者多次
在未分组前,一个Consumer连接就是一个队列
分区
由于分组无法决定那个连接消费消息,所以我们需要设置分组,来保证消息可以指定消费
创建供应商
1 |
|
创建消费者
1 |
|
application.yml
1 | spring: |
使用请求发送消息
1 |
|
启动服务
我们再创建一个服务,配置如下
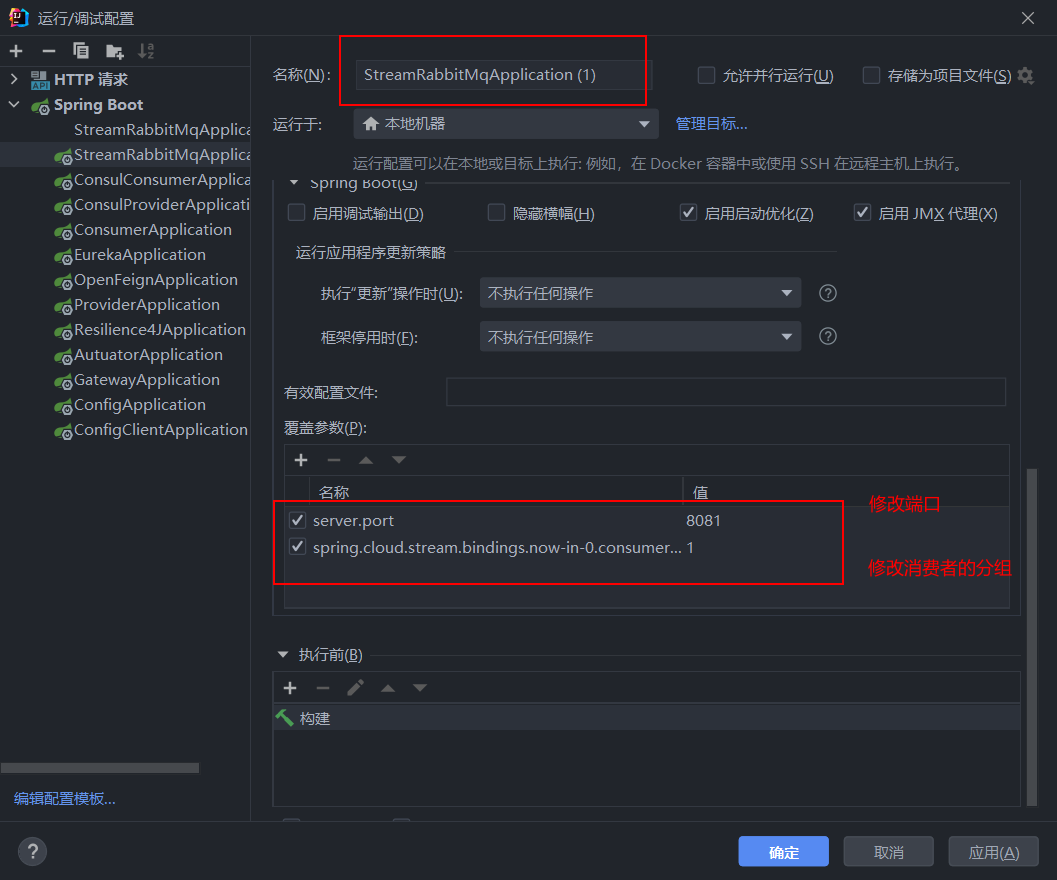
配置完成后,分别启动两个项目

讲解
创建和配置好Bean后,我们来看一下RabbitMq
可以看到,创建了一个名my-topic的路由,该路由下具有两个队列,这两个队列是分组队列,名称都是以myGroup为前缀,
这个是由supplier的required-groups配置决定的
那为什么是两个分组呢,这也是由supplier的partition-count的配置决定的
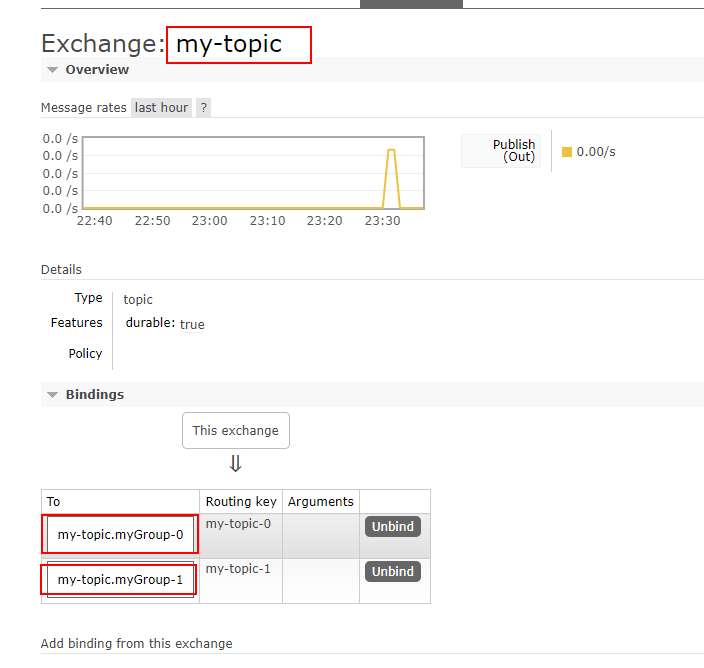
接下来我们详细查看这两个队列
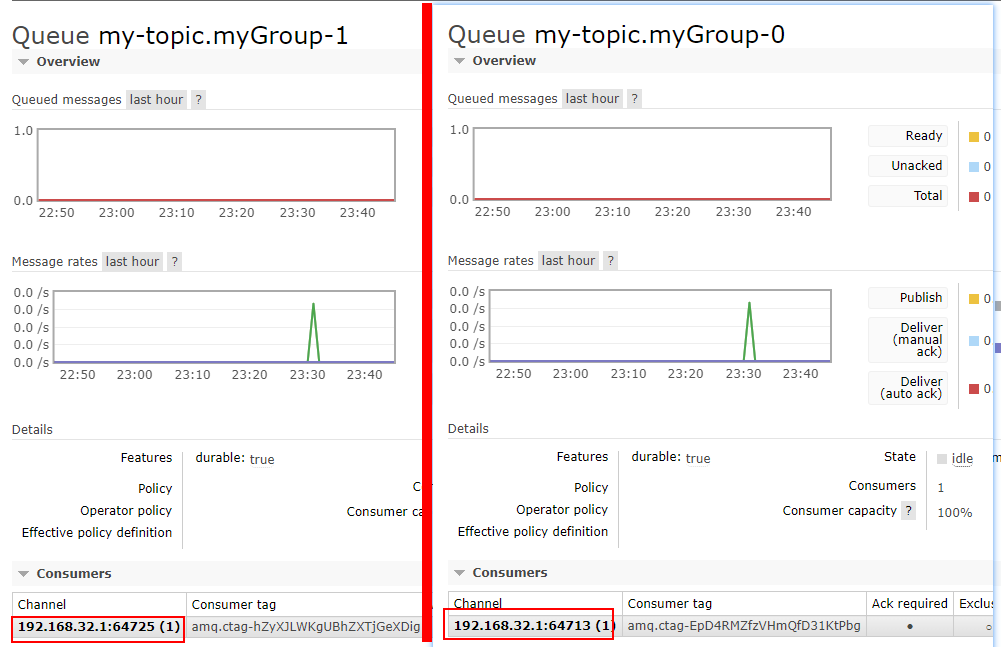
可以看到,两个分组下各有一个连接,那么当我请求url
localhost:8080/send?payload=谢谢你&outputName=noPoll-out-0&index=0
通过控制index的值,就可以指定消息被哪一组的连接消费了
重点
- 分组是依靠消息头中的
partitionKey实现的
外部数据发送到Supplier
在某些情况下,实际数据源可能来自不是绑定器的外部(外国)系统。例如,数据源可能是经典的 REST 端点。我们如何将此类源与 spring-cloud-stream 使用的功能机制连接起来?
Spring Cloud Stream 提供了两种机制,让我们更详细地了解它们
在这里,对于这两个示例,我们将使用称为delegateToSupplier绑定到根 Web 上下文的标准 MVC 端点方法,通过两种不同的机制将传入请求委托给流 - 命令式(通过 StreamBridge)和反应式(通过 EmitterProcessor)。
Supplicat以及Consumer还是以上配置
StreamBridge
-
outputName输出通道名称
-
payload消息体
当我们创建以下接口后,每当我们调用URLlocalhost:8080/send?payload=谢谢你&outputName=date-out-0,都会在输出通道date-out-0发送一条谢谢你的消息
1 |
|
EmitterProcessor
另一种可用于将任意数据发送到输出的方法是使用 Reactor API。
我们需要做的就是声明一个 从反应器 APISupplier<Flux<whatever>>返回EmitterProcessor(有关更多详细信息,请参阅Reactive Functions 支持)以有效地提供实际事件源(外源)和 spring-cloud-stream之间的桥梁。现在,您现在需要做的就是EmitterProcessor通过EmitterProcessor#onNext(data)操作提供数据。
例如,
1 | public class SampleApplication { |
十五,链路追踪
Spring Cloud Sleuth
参考链接:https://zhuanlan.zhihu.com/p/136593164
简介
随着微服务架构的流行,服务按照不同的维度进行拆分,一次请求往往需要涉及到多个服务。互联网应用构建在不同的软件模块集上,这些软件模块,有可能是由不同的团队开发、可能使用不同的编程语言来实现、有可能布在了几千台服务器,横跨多个不同的数据中心。因此,就需要一些可以帮助理解系统行为、用于分析性能问题的工具,以便发生故障的时候,能够快速定位和解决问题。在复杂的微服务架构系统中,几乎每一个前端请求都会形成一个复杂的分布式服务调用链路。一个请求完整调用链可能如下图所示:

随着服务的越来越多,对调用链的分析会越来越复杂。它们之间的调用关系也许如下:

随着业务规模不断增大、服务不断增多以及频繁变更的情况下,面对复杂的调用链路就带来一系列问题:
- 如何快速发现问题?
- 如何判断故障影响范围?
- 如何梳理服务依赖以及依赖的合理性?
- 如何分析链路性能问题以及实时容量规划?
而链路追踪的出现正是为了解决这种问题,它可以在复杂的服务调用中定位问题,还可以在新人加入后台团队之后,让其清楚地知道自己所负责的服务在哪一环。
除此之外,如果某个接口突然耗时增加,也不必再逐个服务查询耗时情况,我们可以直观地分析出服务的性能瓶颈,方便在流量激增的情况下精准合理地扩容。
什么是链路追踪
“链路追踪”一词是在 2010 年提出的,当时谷歌发布了一篇 Dapper 论文:Dapper,大规模分布式系统的跟踪系统,介绍了谷歌自研的分布式链路追踪的实现原理,还介绍了他们是怎么低成本实现对应用透明的。
单纯的理解链路追踪,就是指一次任务的开始到结束,期间调用的所有系统及耗时(时间跨度)都可以完整记录下来。
其实 Dapper 一开始只是一个独立的调用链路追踪系统,后来逐渐演化成了监控平台,并且基于监控平台孕育出了很多工具,比如实时预警、过载保护、指标数据查询等。
除了谷歌的 Dapper,还有一些其他比较有名的产品,比如阿里的鹰眼、大众点评的 CAT、Twitter 的 Zipkin、Naver(著名社交软件LINE的母公司)的 PinPoint 以及国产开源的 SkyWalking(已贡献给 Apache) 等。
什么是 Sleuth
Spring Cloud Sleuth 为 Spring Cloud 实现了分布式跟踪解决方案。兼容 Zipkin,HTrace 和其他基于日志的追踪系统,例如 ELK(Elasticsearch 、Logstash、 Kibana)。
Spring Cloud Sleuth 提供了以下功能:
链路追踪:通过 Sleuth 可以很清楚的看出一个请求都经过了那些服务,可以很方便的理清服务间的调用关系等。性能分析:通过 Sleuth 可以很方便的看出每个采样请求的耗时,分析哪些服务调用比较耗时,当服务调用的耗时随着请求量的增大而增大时, 可以对服务的扩容提供一定的提醒。数据分析,优化链路:对于频繁调用一个服务,或并行调用等,可以针对业务做一些优化措施。可视化错误:对于程序未捕获的异常,可以配合 Zipkin 查看。
术语
-
Span:基本工作单位,一次单独的调用链可以称为一个 Span,Dapper 记录的是 Span 的名称,以及每个 Span 的 ID 和父 ID,以重建在一次追踪过程中不同 Span 之间的关系,图中一个矩形框就是一个 Span,前端从发出请求到收到回复就是一个 Span。

开始跟踪的初始跨度称为
root span。该跨度的 ID 的值等于跟踪 ID。Dapper 记录了 span 名称,以及每个 span 的 ID 和父 span ID,以重建在一次追踪过程中不同 span 之间的关系。如果一个 span 没有父 ID 被称为 root span。所有 span 都挂在一个特定的 Trace 上,也共用一个 trace id。

-
Trace:一系列 Span 组成的树状结构,一个 Trace 认为是一次完整的链路,内部包含 n 多个 Span。Trace 和 Span 存在一对多的关系,Span 与 Span 之间存在父子关系。
举个例子:客户端调用服务 A 、服务 B 、服务 C 、服务 F,而每个服务例如 C 就是一个 Span,如果在服务 C 中另起线程调用了 D,那么 D 就是 C 的子 Span,如果在服务 D 中另起线程调用了 E,那么 E 就是 D 的子 Span,这个 C -> D -> E 的链路就是一条 Trace。如果链路追踪系统做好了,链路数据有了,借助前端解析和渲染工具,可以达到下图中的效果:

-
Annotation/Event:用来及时记录一个事件的存在,一些核心 annotations 用来定义一个请求的开始和结束。
- cs-Client-Sent:客户端发送一个请求,这个注解描述了Span的开始
- sr-Server Received:服务端获得请求并准备开始处理它,如果将sr减去cs时间戳,便可得到网络传输的时间
- ss-Server Sent:服务端发送响应,该注解表明请求处理的完成(当请求返回客户端),用ss的时间戳减去sr时间戳,便可以得到服务器请求的时间
- cr-Client Received:客户端接收响应,此时Span结束,如果cr的时间戳减去cs时间戳,便可以得到整个请求所消耗的时间
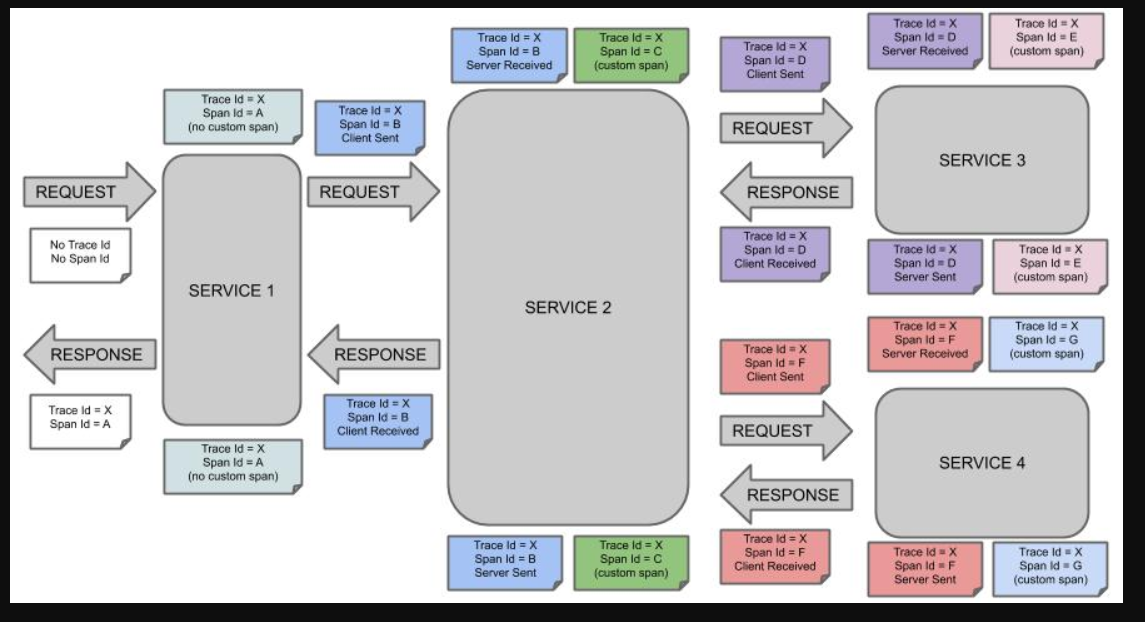
每种颜色表示一个跨度(有七个跨度 - 从A到G)。请考虑以下注意事项:
Trace Id = X
Span Id = D
Client Sent
此注释表示当前跨度将Trace Id设置为X并将Span Id设置为D。此外,从 RPC 的角度来看,Client Sent事件发生了。
让我们考虑更多注意事项:
Trace Id = X
Span Id = A
(no custom span)Trace Id = X
Span Id = C
(custom span)
您可以继续使用创建的跨度(带有no custom span指示的示例),也可以手动创建子跨度(带有custom span指示的示例)。
下图显示了跨度的父子关系:
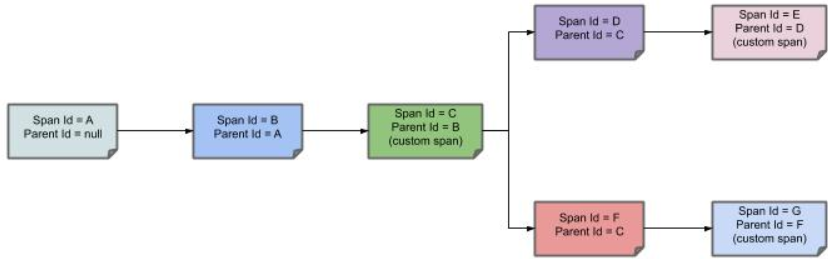
快速开始
前提项目
-
Eureka
-
Provider
-
controller
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
public class SleuthController {
RestTemplate restTemplate;
private static final Logger log = LoggerFactory.getLogger(SleuthController.class);
public String hello(){
log.info("hello");
return "hello sleuth";
}
public String link(){
String rsp = restTemplate.getForObject("http://localhost:8080/sleuth/api", String.class);
log.info(rsp);
return "hello sleuth";
}
public String api(){
log.info("调用api");
return "hello api";
}
}
-
一个注册中心,一个提供接口调用的服务,这两个项目可以参考以上笔记创建
创建项目
首先我们创建Slieuth项目,引入以下依赖
- web
- openfeign
- eureka
- sleuth
1 | <dependencies> |
发起调用
我们向Sleuth服务发起请求localhost:2222/link-api
我们分别观察Sleuth服务和Provider服务的日志
Sleuth

Provider
api接口链式调用,使用restTemple二次调用接口,打印两次

可以看到在日志中打印出来的Trace和Span的ID,在发起请求的Sleuth服务中可以看到生成了本次调用的TraceID,但是并未生成SpanID(Span栏位使用了TraceID),而在Provider服务中,可以看到熟悉的TraceID,但是每一次调用的SpanID不同。
所以Span组成了Trace,一个Trace记录了本次调用的调用链,可以结合一下这张图片理解。
自定义Span
创建Span
Spring Cloud SleuthTracer创建了一个实例。为了使用它,可以自动装配它。
1 |
|
自此我们就创建好了一个Span,并且我们可以在Span结束之前自定义它。
连续Span
有时,您不想创建一个新的跨度,而是想继续一个。这种情况的一个例子可能如下:
- AOP:如果在达到方面之前已经创建了一个跨度,您可能不想创建一个新的跨度。
要继续跨度,您可以将跨度存储在一个线程中并将其传递给另一个线程,如下例所示。
我们只需将想要连续使用的Span,将参数转递给下一个方法即可
1 | /** |
创建父级Span的子级Span
与连续使用 Span相似,我们需要将父级Span作为参数传递下去,
然后通过Span childSpan = tracer.nextSpan(fatherSpan);得到子级Span
1 | /** |
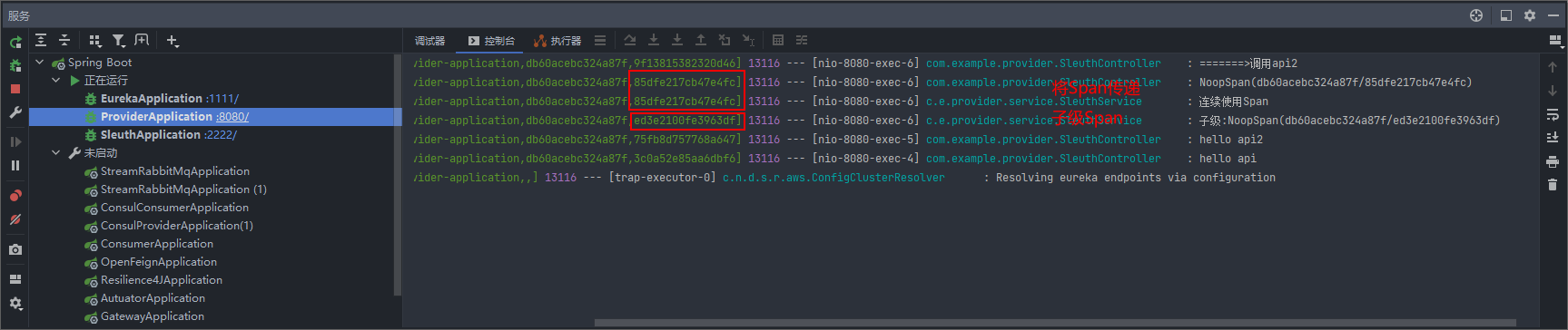
注意:
-
只要我们在代码中创建了Span,就需要将其写入到
Trace,tracer.withSpan(childSpan)
-
创建的Span,需要手动关闭,否则该Span将不会报告(无效)
span.end();
注解
如果您不想手动创建本地跨度,则可以使用@NewSpan注释。此外,我们提供了@SpanTag以自动化方式添加标签的注释。
现在我们可以考虑一些使用示例。
1 |
|
注释不带任何参数的方法会导致创建一个新的跨度,其名称等于注释的方法名称。
1 |
|
如果您在注释中提供值(直接或通过设置name参数),则创建的跨度将提供的值作为名称。
1 | // method declaration |
ZipKin
简介

Zipkin 是 Twitter 公司开发贡献的一款开源的分布式实时数据追踪系统(Distributed Tracking System),基于 Google Dapper 的论文设计而来,其主要功能是聚集各个异构系统的实时监控数据。
它可以收集各个服务器上请求链路的跟踪数据,并通过 Rest API 接口来辅助我们查询跟踪数据,实现对分布式系统的实时监控,及时发现系统中出现的延迟升高问题并找出系统性能瓶颈的根源。除了面向开发的 API 接口之外,它还提供了方便的 UI 组件,每个服务向 Zipkin 报告计时数据,Zipkin 会根据调用关系生成依赖关系图,帮助我们直观的搜索跟踪信息和分析请求链路明细。Zipkin 提供了可插拔数据存储方式:In-Memory、MySql、Cassandra 以及 Elasticsearch。
分布式跟踪系统还有其他比较成熟的实现,例如:Naver 的 PinPoint、Apache 的 HTrace、阿里的鹰眼 Tracing、京东的 Hydra、新浪的 Watchman,美团点评的 CAT,Apache 的 SkyWalking 等。
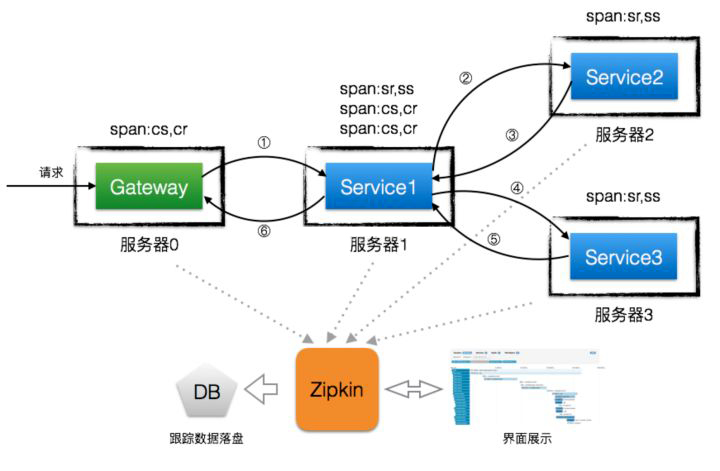
工作原理
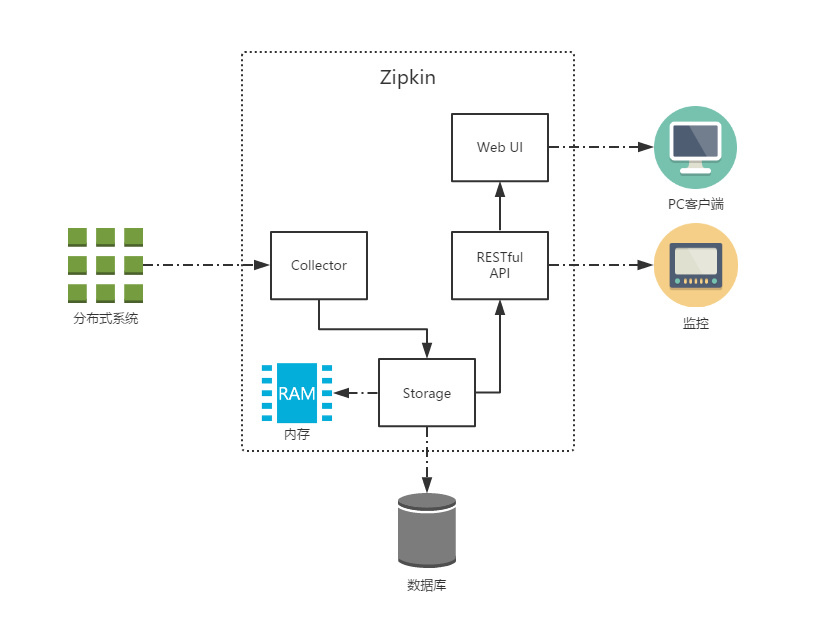
共有四个组件构成了 Zipkin:
Collector:收集器组件,处理从外部系统发送过来的跟踪信息,将这些信息转换为 Zipkin 内部处理的 Span 格式,以支持后续的存储、分析、展示等功能。Storage:存储组件,处理收集器接收到的跟踪信息,默认将信息存储在内存中,可以修改存储策略使用其他存储组件,支持 MySQL,Elasticsearch 等。Web UI:UI 组件,基于 API 组件实现的上层应用,提供 Web 页面,用来展示 Zipkin 中的调用链和系统依赖关系等。RESTful API:API 组件,为 Web 界面提供查询存储中数据的接口。
Zipkin 分为两端,一个是 Zipkin 服务端,一个是 Zipkin 客户端,客户端也就是微服务的应用,客户端会配置服务端的 URL 地址,一旦发生服务间的调用的时候,会被配置在微服务里面的 Sleuth 的监听器监听,并生成相应的 Trace 和 Span 信息发送给服务端。发送的方式有两种,一种是消息总线的方式如 RabbitMQ 发送,还有一种是 HTTP 报文的方式发送。
前置准备
这里我们使用Elasticsearch 作为ZipKin的持久化库,使用RabbitMQ作为客户端和服务端消息传递的方式
注意:Elasticsearch 和其可视化工具Kibana的大版本需要保持一致
Elasticsearch
dockerhub:https://registry.hub.docker.com/_/elasticsearch?tab=description
- 拉取镜像
docker pull elasticsearch:7.14.2
- 启动服务
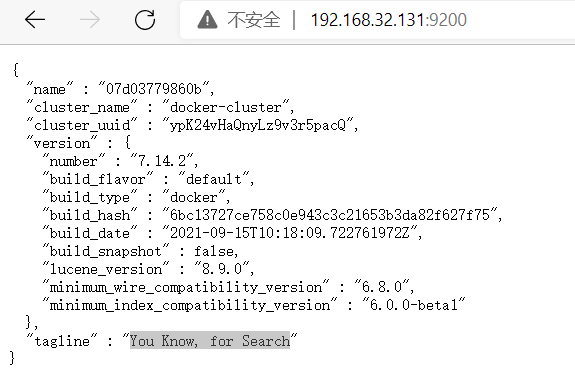
docker run -d --name elasticsearch --net ESwork -p 9200:9200 -p 9300:9300 -e “discovery.type=single-node” elasticsearch:7.14.2
访问URL192.168.32.131:9200验证是否启动成功
Kibana
文档:https://www.elastic.co/guide/cn/kibana/current/index.html
dockerhub:https://registry.hub.docker.com/_/kibana?tab=description
- 拉取镜像
docker pull kibana:7.14.2
- 启动服务
docker run -d --name kibana --net ESwork -p 5601:5601 -e ELASTICSEARCH_URL=192.168.32.131:9200 kibana:7.14.2
- 进入
Kibana服务修改配置文件,设置Elasticsearch地址
docker exec -it kibana bash
vi /usr/share/kibana/config/kibana.yml
将红框部分设置为Elasticsearch集群地址
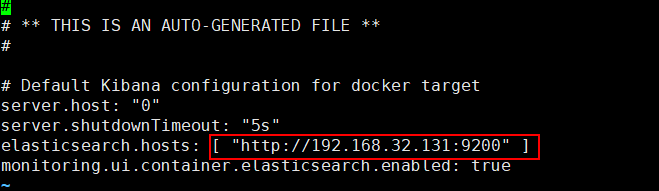
接下来我们只需访问http://192.168.32.131:5601,点击左侧菜单的Dev Tools即可查询Elasticsearch
RabbitMQ
- 拉取服务
docker pull rabbitmq:3-management
- 启动服务
docker run -d --name rabbit -p 5672:5762 -p 15672:15672 rabbitmq:3-management
安装ZipKin
dockerhub:https://registry.hub.docker.com/r/openzipkin/zipkin
- docker获取镜像
docker pull openzipkin/zipkin
- 启动服务
docker run -d -p 9411:9411 --name zipkin -e ES_HOSTS=192.168.32.131 -e STORAGE_TYPE=elasticsearch -e ES_HTTP_LOGGING=BASIC -e RABBIT_URI=amqp://xpp011:xpp011@192.168.32.131:5672 openzipkin/zipkin:latest
- ES_HOSTS Elasticsearch服务地址
- STORAGE_TYPE 数据存储方式
- ES_HTTP_LOGGING 日志打印级别
- RABBIT_URI Rabbit连接地址 (amqp://账号:密码@连接地址)
访问URLhttp://192.168.32.131:9411/zipkin,验证是否启动成功
创建ZipKin客户端
引入以下依赖
配置以下信息
1 | spring: |
可视化
配置完成后我们可以启动该服务
访问zipkin地址http://192.168.32.131:9411/zipkin,即可看到访问信息
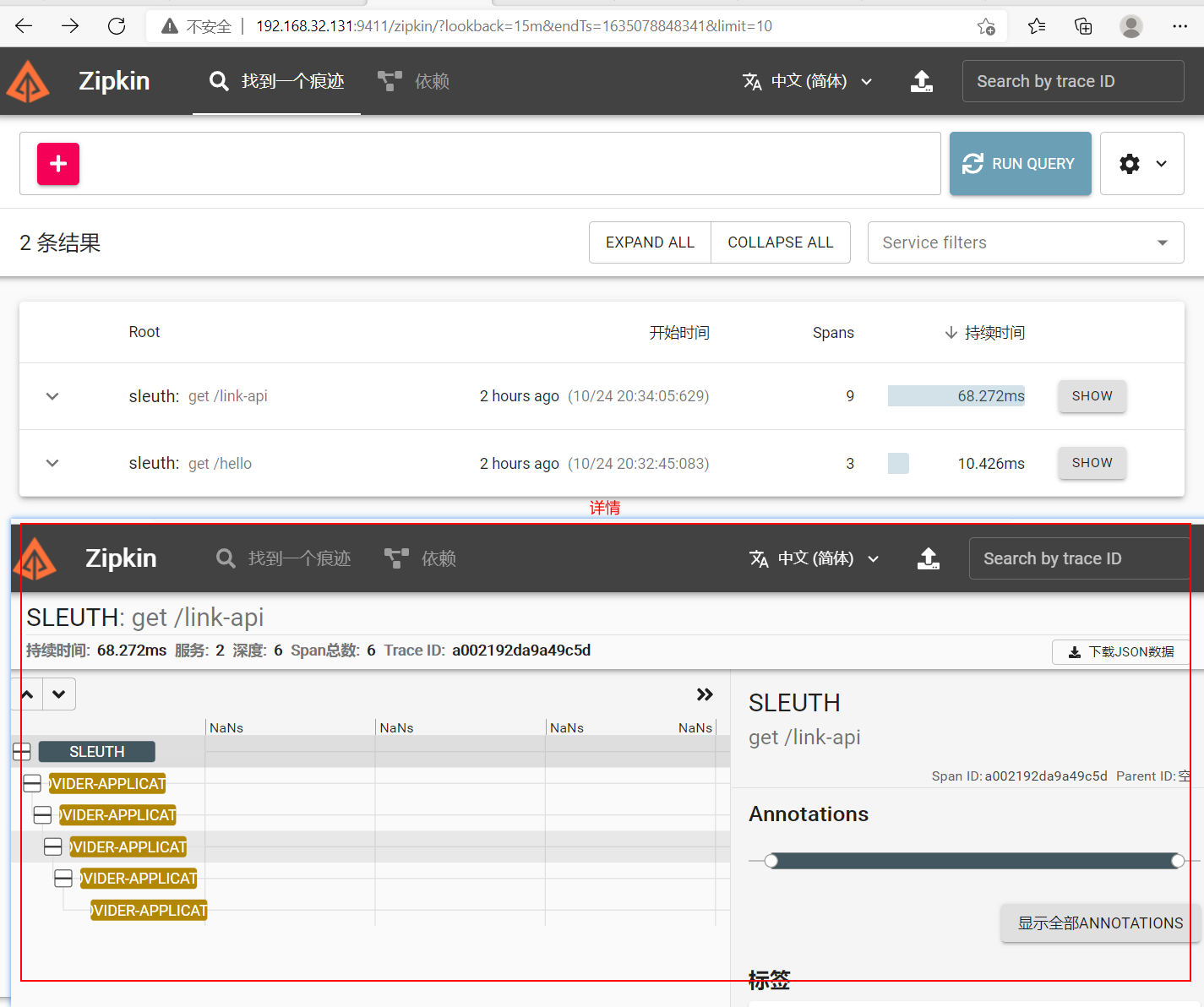
持久化
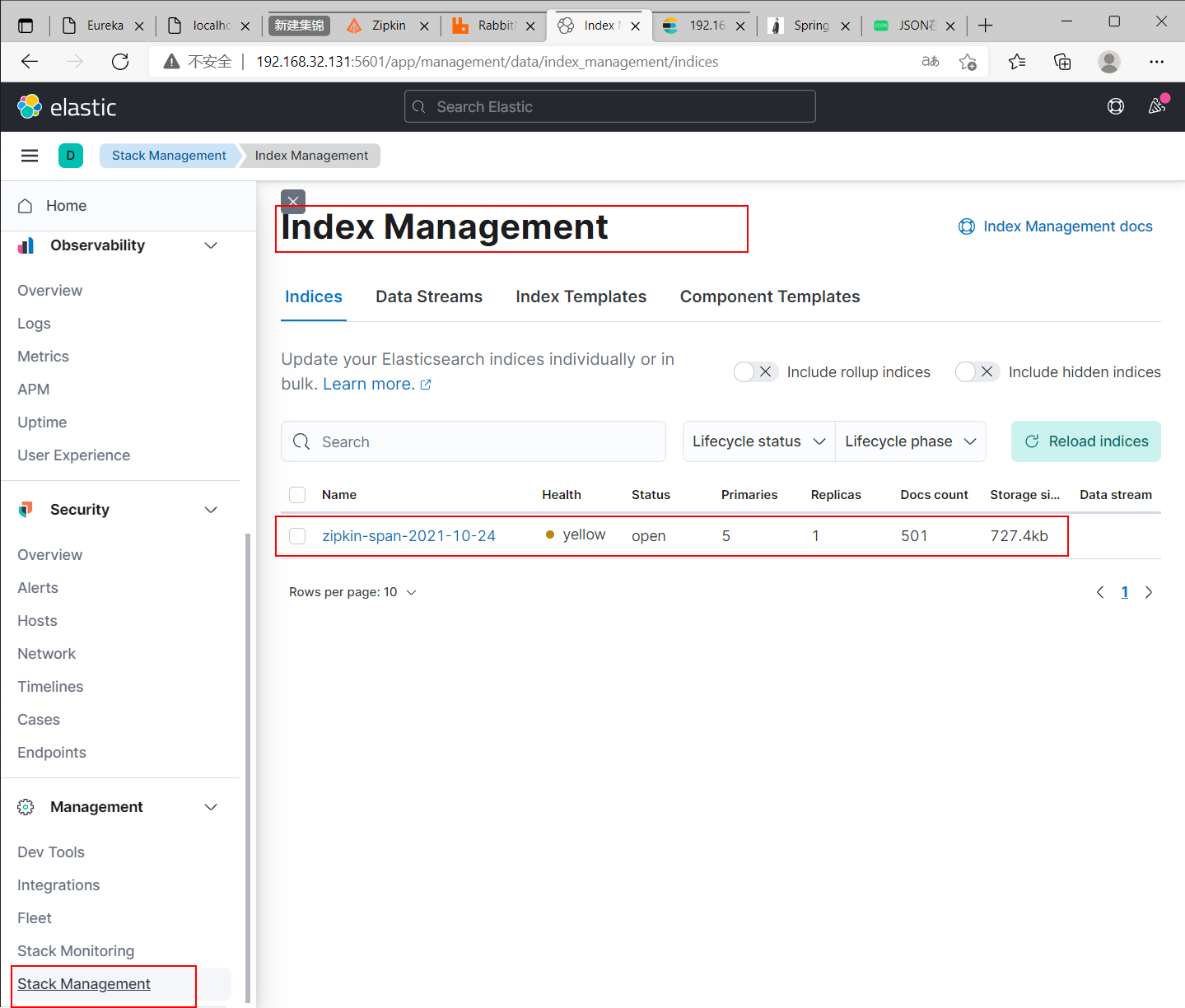
查看Kibanahttp://192.168.32.131:5601/,根据图片菜单 查看Elasticsearch指标信息
十六,Alibbaba
简介
Spring Cloud Alibaba 致力于提供微服务开发的一站式解决方案。此项目包含开发分布式应用微服务的必需组件,方便开发者通过 Spring Cloud 编程模型轻松使用这些组件来开发分布式应用服务。
依托 Spring Cloud Alibaba,只需要添加一些注解和少量配置,就可以将 Spring Cloud 应用接入阿里微服务解决方案,通过阿里中间件来迅速搭建分布式应用系统。
Spring Cloud Alibaba 功能
- 服务限流降级 Sentinel:支持 WebServlet,WebFlux,OpenFeign,RestTemplate,Dubbo,Gateway,Zuul 限流降级功能的接入。可以在运行时通过控制台实时修改限流降级规则,并且还支持限流降级度量指标监控。
- 服务注册与发现 Nacos:适配 Spring Cloud 服务注册与发现标准,默认集成了 Ribbon 的支持。
- 分布式配置管理 Nacos:支持分布式系统中的外部化配置,配置更改时自动刷新。
- RPC 服务 Dubbo:扩展 Spring Cloud 客户端 RestTemplate 和 OpenFeign 以支持调用 Dubbo RPC 服务。
- 消息驱动 RocketMQ:基于 Spring Cloud Stream 为微服务应用构建消息驱动能力。
- 分布式事务 Seata:支持高性能且易于使用的分布式事务解决方案。
- 阿里云对象存储 OSS:大规模,安全,低成本,高度可靠的云存储服务。支持随时随地在任何应用程序中存储和访问任何类型的数据。
- 分布式任务调度 SchedulerX:提供秒级、精准、高可靠、高可用的定时(基于 Cron 表达式)任务调度服务。同时提供分布式的任务执行模型,如网格任务。网格任务支持海量子任务均匀分配到所有 Worker(schedulerx-client)上执行。
- 阿里云短信服务 SMS:覆盖全球的短信服务,友好、高效、智能的通讯能力,帮助企业迅速搭建客户触达通道。
Spring Cloud Alibaba 组件
Nacos:阿里巴巴开源产品,一个更易于构建云原生应用的动态服务发现、配置管理和服务管理平台。Sentinel:面向分布式服务架构的轻量级流量控制产品,把流量作为切入点,从流量控制、熔断降级、系统负载保护等多个维度保护服务的稳定性。RocketMQ:一款开源的分布式消息系统,基于高可用分布式集群技术,提供低延时的、高可靠的消息发布与订阅服务。Dubbo:Apache Dubbo™ 是一款高性能 Java RPC 框架。Seata:阿里巴巴开源产品,一个易于使用的高性能微服务分布式事务解决方案。Alibaba Cloud ACM:一款在分布式架构环境中对应用配置进行集中管理和推送的应用配置中心产品。Alibaba Cloud OSS:阿里云对象存储服务(Object Storage Service,简称 OSS),是阿里云提供的海量、安全、低成本、高可靠的云存储服务。您可以在任何应用、任何时间、任何地点存储和访问任意类型的数据。Alibaba Cloud SchedulerX:阿里中间件团队开发的一款分布式任务调度产品,提供秒级、精准、高可靠、高可用的定时(基于 Cron 表达式)任务调度服务。Alibaba Cloud SMS:覆盖全球的短信服务,友好、高效、智能的互联化通讯能力,帮助企业迅速搭建客户触达通道。
什么是注册中心
服务注册中心是服务实现服务化管理的核心组件,类似于目录服务的作用,主要用来存储服务信息,譬如提供者 url 串、路由信息等。服务注册中心是微服务架构中最基础的设施之一。
注册中心可以说是微服务架构中的“通讯录”,它记录了服务和服务地址的映射关系。在分布式架构中,服务会注册到这里,当服务需要调用其它服务时,就到这里找到服务的地址,进行调用。
简单理解就是:在没有注册中心时候,服务间调用需要知道被当服务调方的具体地址(写死的 ip:port)。更换部署地址,就不得不修改调用当中指定的地址。而有了注册中心之后,每个服务在调用别人的时候只需要知道服务名称(软编码)就好,地址都会通过注册中心根据服务名称获取到具体的服务地址进行调用。

举个现实生活中的例子,比如说,我们手机中的通讯录的两个使用场景:
当我想给张三打电话时,那我需要在通讯录中按照名字找到张三,然后就可以找到他的手机号拨打电话。—— 服务发现
李四办了手机号并把手机号告诉了我,我把李四的号码存进通讯录,后续,我就可以从通讯录找到他。—— 服务注册
通讯录 —— ?什么角色(服务注册中心)
总结:服务注册中心的作用就是服务的注册和服务的发现。
常见的注册中心
- Netflix Eureka
- Alibaba Nacos
- HashiCorp Consul
- Apache ZooKeeper
- CoreOS Etcd
- CNCF CoreDNS
| 特性 | Eureka | Nacos | Consul | Zookeeper |
|---|---|---|---|---|
| CAP | AP | CP + AP | CP | CP |
| 健康检查 | Client Beat | TCP/HTTP/MYSQL/Client Beat | TCP/HTTP/gRPC/Cmd | Keep Alive |
| 雪崩保护 | 有 | 有 | 无 | 无 |
| 自动注销实例 | 支持 | 支持 | 不支持 | 支持 |
| 访问协议 | HTTP | HTTP/DNS | HTTP/DNS | TCP |
| 监听支持 | 支持 | 支持 | 支持 | 支持 |
| 多数据中心 | 支持 | 支持 | 支持 | 不支持 |
| 跨注册中心同步 | 不支持 | 支持 | 支持 | 不支持 |
| SpringCloud集成 | 支持 | 支持 | 支持 | 支持 |
为什么需要注册中心
了解了什么是注册中心,那么我们继续谈谈,为什么需要注册中心。在分布式系统中,我们不仅仅是需要在注册中心找到服务和服务地址的映射关系这么简单,我们还需要考虑更多更复杂的问题:
- 服务注册后,如何被及时发现
- 服务宕机后,如何及时下线
- 服务如何有效的水平扩展
- 服务发现时,如何进行路由
- 服务异常时,如何进行降级
- 注册中心如何实现自身的高可用
这些问题的解决都依赖于注册中心。简单看,注册中心的功能有点类似于 DNS 服务器或者负载均衡器,而实际上,注册中心作为微服务的基础组件,可能要更加复杂,也需要更多的灵活性和时效性。所以我们还需要学习更多 Spring Cloud 微服务组件协同完成应用开发。
注册中心解决了以下问题:
- 服务管理
- 服务之间的自动发现
- 服务的依赖关系管理
Nacos
文档:什么是 Nacos
简介
Nacos 是 Alibaba 公司推出的开源工具,用于实现分布式系统的服务发现与配置管理。英文全称 Dynamic Naming and Configuration Service,Na 为 Naming/NameServer 即注册中心,co 为 Configuration 即配置中心,Service 是指该注册/配置中心都是以服务为核心。服务(Service)是 Nacos 世界的一等公民。
官网是这样说的:一个更易于构建云原生应用的动态服务发现、配置管理和服务管理平台。
Nacos 致力于发现、配置和管理微服务。Nacos 提供了一组简单易用的特性集,可以快速实现动态服务发现、服务配置、服务元数据及流量管理。
Nacos 可以更敏捷和容易地构建、交付和管理微服务平台。 Nacos 是构建以“服务”为中心的现代应用架构的服务基础设施。
使用 Nacos 简化服务发现、配置管理、服务治理及管理的解决方案,让微服务的发现、管理、共享、组合更加容易。
Nacos 官网:https://nacos.io/zh-cn/
Github:https://github.com/alibaba/nacos
安装
docker安装
docker run --name nacos-e MODE=standalone -p 8848:8848 -d nacos/nacos-server:2.0.2
jar
https://github.com/alibaba/nacos/releases,在Girhub中可以获取各个环境的安装文件
环境
- JDK1.8+
- Maven2.3+
windowns将zip解压后,进入bin目录双击startup.cmd文件即可
访问http://loaclhost:8848/nacos,输入账户和密码(都是nacos)

配置中心
在使用客户端拉取配置之前,我们需要先在nacos创建一个配置
配置集 ID
Nacos 中的某个配置集的 ID。配置集 ID 是组织划分配置的维度之一。Data ID 通常用于组织划分系统的配置集。一个系统或者应用可以包含多个配置集,每个配置集都可以被一个有意义的名称标识。Data ID 通常采用类 Java 包(如 com.taobao.tc.refund.log.level)的命名规则保证全局唯一性。此命名规则非强制。
配置分组
Nacos 中的一组配置集,是组织配置的维度之一。通过一个有意义的字符串(如 Buy 或 Trade )对配置集进行分组,从而区分 Data ID 相同的配置集。当您在 Nacos 上创建一个配置时,如果未填写配置分组的名称,则配置分组的名称默认采用 DEFAULT_GROUP 。配置分组的常见场景:不同的应用或组件使用了相同的配置类型,如 database_url 配置和 MQ_topic 配置。
可以看到我们配置了一个名称为example.yaml分组为DEFAULT_GREP的配置文件
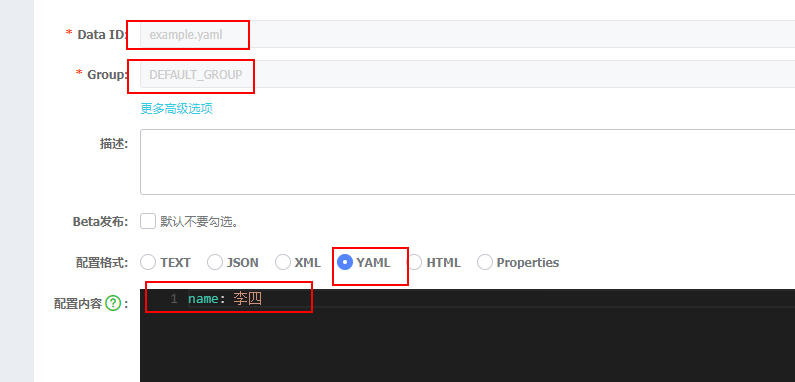
nacos客户端
我们创建一个Spring项目,引入以下依赖
- spring-cloud-starter-bootstrap
- spring-cloud-starter-alibaba-nacos-config
- spring-boot-starter-web
以下注释还对SpringCloud项目依赖结果做了说明
1 |
|
Server端安装启动完成后,我们开始创建客户端,针对nacos进行服务发现和配置拉取
配置拉取
由于配置信息在配置中心中,启动时需要提取配置信息加载applicat.yml的配置,Spring提供了booystrap.yml引导配置文件
在bootstrap.yml中我需要提前申明应用名称,以及配置中心地址
1 | spring: |
配置完成后就可以在配置中心拉取配置了
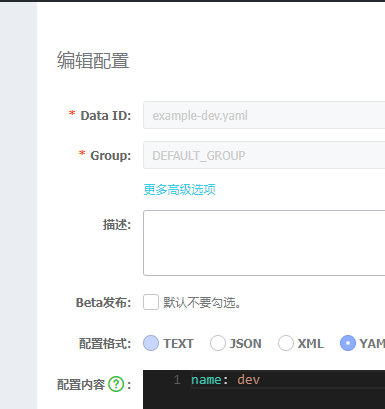
当然配置中心也支持不同环境${spring.application.name}-${profile}.${file-extension:properties}的配置文件
我们在配置文件中配置${spring.profiles.active}即可确认活跃的配置文件是那一项
配置中心
nacos的配置中心和注册中心是一起的
这边我们直接在客户端导入依赖
1 | <dependency> |
简单的配置${spring.cloud.discovery.server-addr}注册中心地址
1 | spring: |
查看nacos就可以发现服务已经注册上去了

Sentinel
随着微服务的流行,服务和服务之间的稳定性变得越来越重要。 Sentinel 以流量为切入点,从流量控制、熔断降级、系统负载保护等多个维度保护服务的稳定性。
Sentinel 具有以下特征:
- 丰富的应用场景: Sentinel 承接了阿里巴巴近 10 年的双十一大促流量的核心场景,例如秒杀(即突发流量控制在系统容量可以承受的范围)、消息削峰填谷、实时熔断下游不可用应用等。
- 完备的实时监控: Sentinel 同时提供实时的监控功能。您可以在控制台中看到接入应用的单台机器秒级数据,甚至 500 台以下规模的集群的汇总运行情况。
- 广泛的开源生态: Sentinel 提供开箱即用的与其它开源框架/库的整合模块,例如与 Spring Cloud、Dubbo、gRPC 的整合。您只需要引入相应的依赖并进行简单的配置即可快速地接入 Sentinel。
- 完善的 SPI 扩展点: Sentinel 提供简单易用、完善的 SPI 扩展点。您可以通过实现扩展点,快速的定制逻辑。例如定制规则管理、适配数据源等。
控制台
Sentinel 控制台提供一个轻量级的控制台,它提供机器发现、单机资源实时监控、集群资源汇总,以及规则管理的功能。您只需要对应用进行简单的配置,就可以使用这些功能。
下载地址:https://github.com/alibaba/Sentinel/releases
下载完成后我们启动它
java -Dserver.port=8080 -Dcsp.sentinel.dashboard.server=localhost:8080 -Dproject.name=sentinel-dashboard -jar sentinel-dashboard-1.8.2.jar
访问192.168.32.131:8080
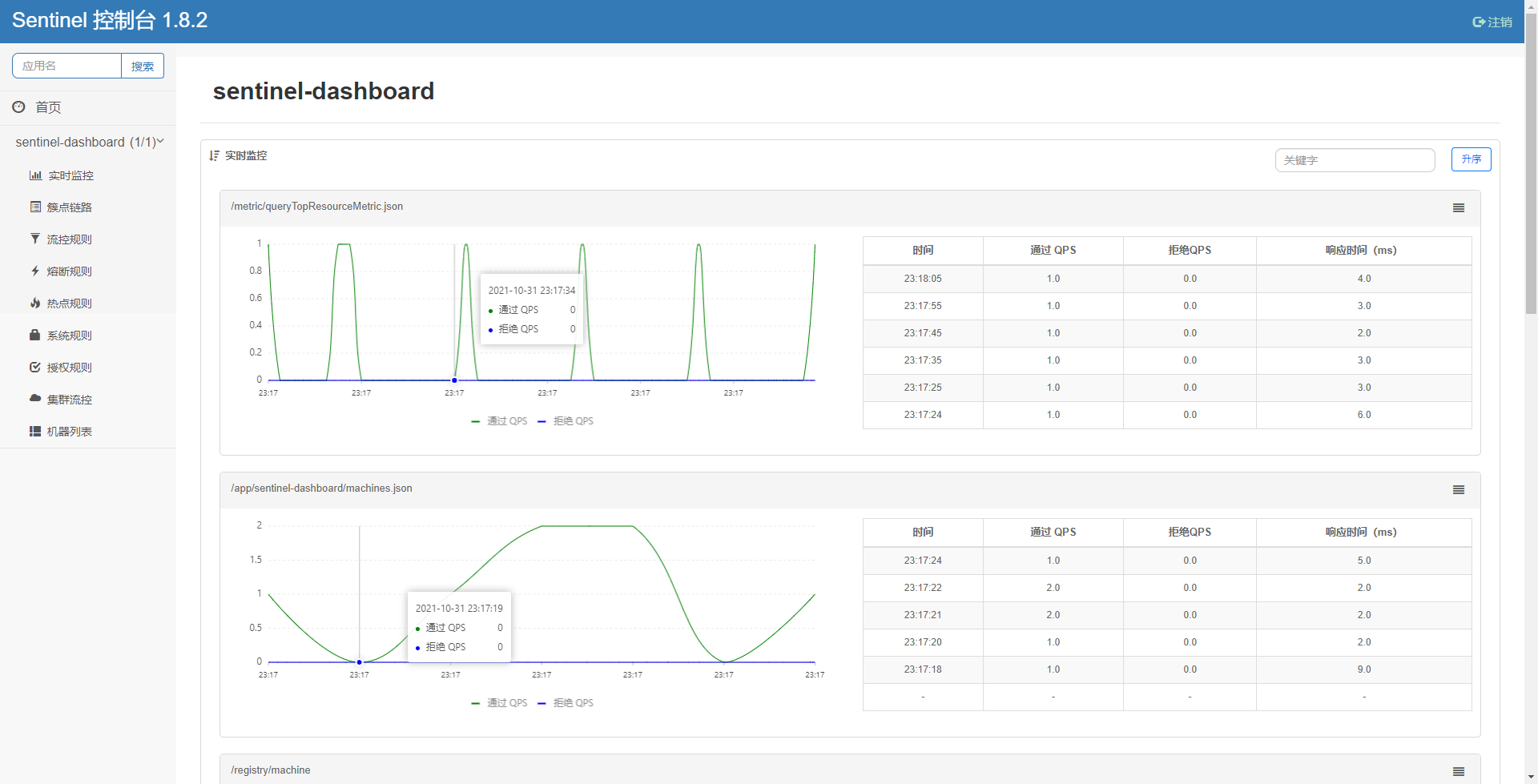
客户端
创建客户端连接到Sentinel控制台.
引入依赖
1 | <!-- https://mvnrepository.com/artifact/com.alibaba.cloud/spring-cloud-starter-alibaba-sentinel --> |
配置Sentinel相关信息
-
spring.cloud.sentinel.transport.port端口配置会在应用对应的机器上启动一个 Http Server,该 Server 会与 Sentinel 控制台做交互。比如 Sentinel 控制台添加了1个限流规则,会把规则数据 push 给这个 Http Server 接收,Http Server 再将规则注册到 Sentinel 中。
-
spring.cloud.sentinel.transport.dashboard控制台地址
-
spring.cloud.sentinel.log.dir日志输出地址
1 | spring: |
创建测试的Controller
-
@SentinelResource@SentinelResource 注解用来标识资源是否被限流、降级。上述例子上该注解的属性 ‘hello’ 表示资源名。
@SentinelResource 还提供了其它额外的属性如
blockHandler,blockHandlerClass,fallback用于表示限流或降级的操作,更多内容可以参考 Sentinel注解支持。
1 |
|
这样我们的客户端就创建好了
注意当我们启动服务后,在控制台没有看到该服务,可以尝试请求一下服务接口,激活一下
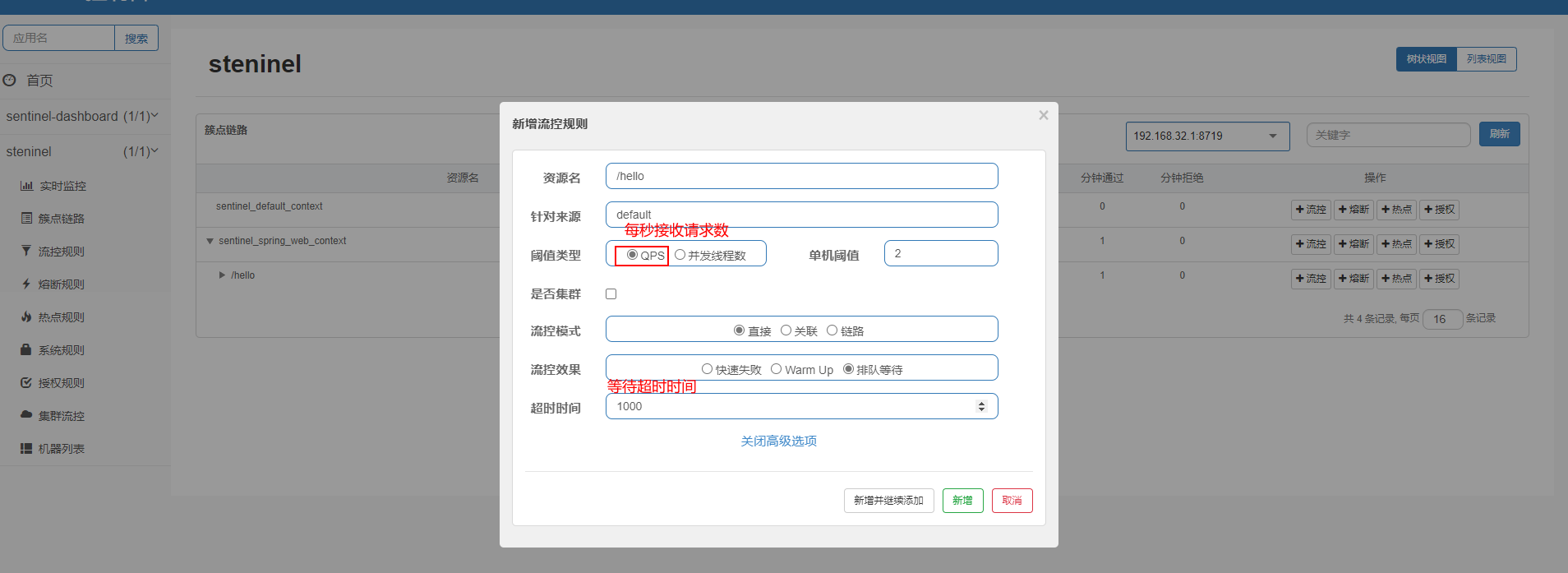
控制台创建规则
在簇点链路菜单下可以针对某一资源创建限流、熔断策略、热点、授权等操作

创建限流规则
测试
我们连续接口hello15次
1 |
|
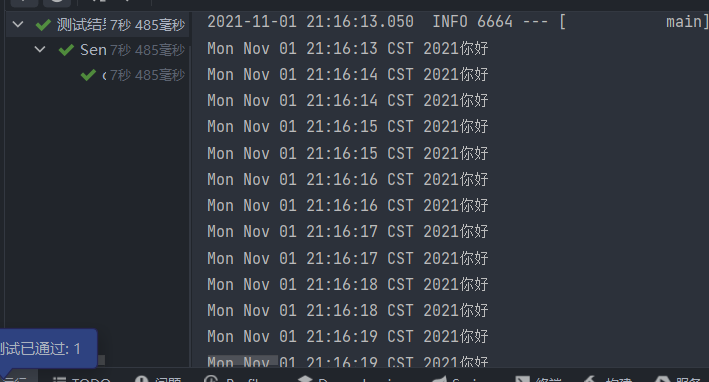
可以看到控制台是每一秒打印两次,也就是接口每一秒受理两次请求

